Nguồn gốc: New Zhiyuan
 Nguồn hình ảnh: Được tạo bởi Unbounded AI
Nguồn hình ảnh: Được tạo bởi Unbounded AI
Để giải nén “hộp đen” của các mô hình lớn, nhóm giải thích Anthropic đã xuất bản một bài báo mô tả cách họ có thể đào tạo một mô hình mới để hiểu một mô hình đơn giản.
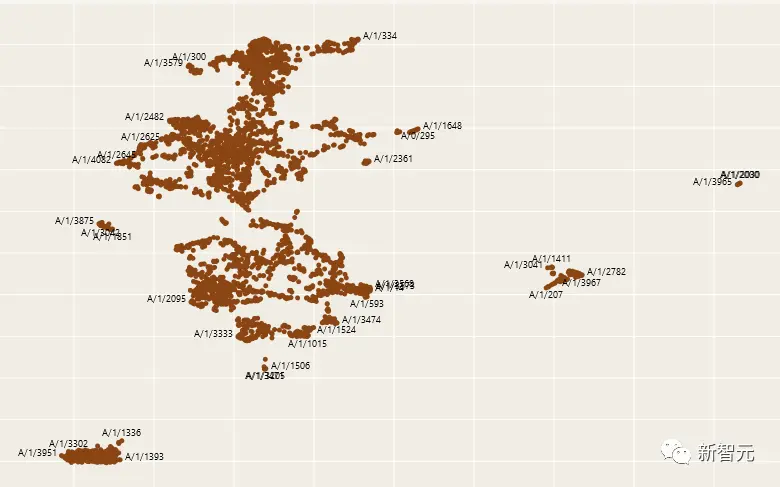
Một nghiên cứu được công bố bởi Anthropic tuyên bố có thể nhìn thấy linh hồn của trí tuệ nhân tạo. Nó trông như thế này:
 Địa chỉ:
Địa chỉ:
Theo các nhà nghiên cứu, mô hình mới có thể dự đoán và hiểu chính xác nguyên lý hoạt động và cơ chế thành phần của các tế bào thần kinh trong mô hình ban đầu.
Nhóm giải thích của Anthropic gần đây đã thông báo rằng họ đã phân tách thành công một không gian tính năng chiều cao trừu tượng trong một hệ thống AI mô phỏng.
** Tạo một AI có thể giải thích để hiểu “hộp đen AI”**
Đầu tiên, các nhà nghiên cứu đã đào tạo một AI 512 tế bào thần kinh rất đơn giản để dự đoán văn bản, sau đó đào tạo một AI khác gọi là “bộ mã hóa tự động” để dự đoán mô hình kích hoạt của AI đầu tiên.
Bộ mã hóa tự động được yêu cầu xây dựng một tập hợp các tính năng (tương ứng với số lượng tế bào thần kinh trong AI chiều cao hơn) và dự đoán cách các tính năng này sẽ ánh xạ đến tế bào thần kinh trong AI thực.
Người ta thấy rằng trong khi các tế bào thần kinh trong AI ban đầu không dễ hiểu, các tế bào thần kinh mô phỏng trong AI mới (tức là “tính năng”) là đơn nghĩa và mỗi tính năng đại diện cho một khái niệm hoặc chức năng cụ thể.
Ví dụ, đặc điểm # 2663 đại diện cho khái niệm “Chúa”.
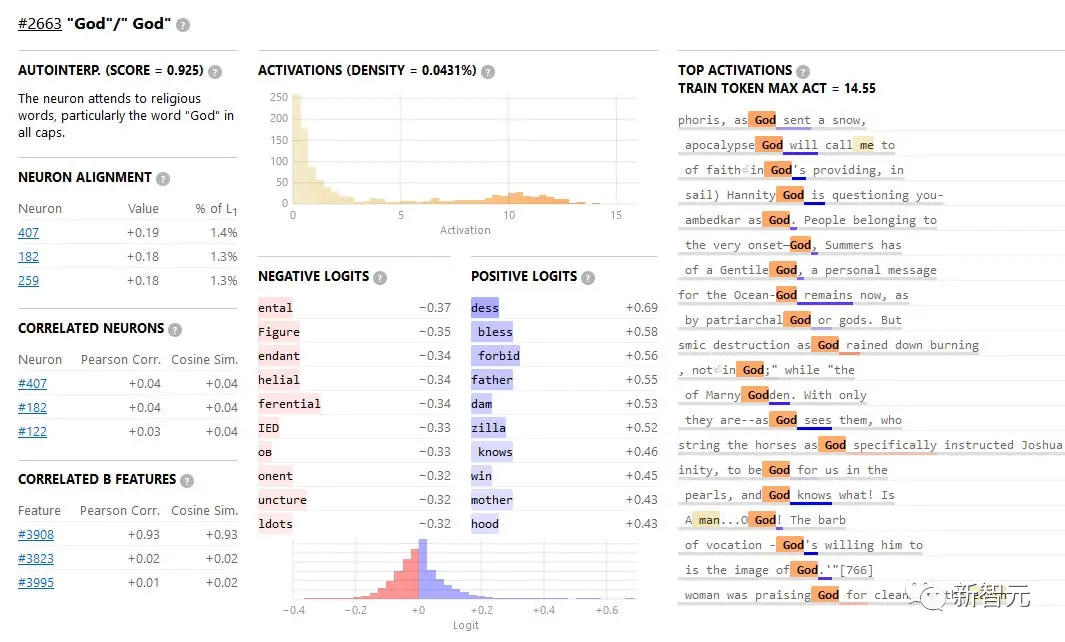 Cụm từ huấn luyện mạnh nhất để kích hoạt nó đến từ hồ sơ của Josephus nói rằng “Khi trận bão tuyết đổ xuống Chúa, anh ấy đến Sepphoris”.
Cụm từ huấn luyện mạnh nhất để kích hoạt nó đến từ hồ sơ của Josephus nói rằng “Khi trận bão tuyết đổ xuống Chúa, anh ấy đến Sepphoris”.
Bạn có thể thấy rằng các kích hoạt ở trên cùng là tất cả về các cách sử dụng khác nhau của “Chúa”.
Tế bào thần kinh mô phỏng này dường như được tạo thành từ một tập hợp các tế bào thần kinh thực, bao gồm 407, 182 và 259.
Bản thân những tế bào thần kinh thực sự này ít liên quan đến “Chúa”, ví dụ, Neuron 407 phản hồi chủ yếu với các chữ cái Latinh không phải tiếng Anh (đặc biệt là các chữ cái Latinh được nhấn mạnh) và văn bản không chuẩn (như thẻ HTML).
Nhưng ở cấp độ tính năng, mọi thứ đều theo thứ tự và khi tính năng 2663 được kích hoạt, nó sẽ tăng xác suất “ban phước”, “cấm”, “chết tiệt” hoặc “-zilla” xuất hiện trong văn bản.
AI không phân biệt khái niệm “Chúa” với “Chúa” trong tên của con quái vật. Điều này có thể là do AI ngẫu hứng không có đủ tài nguyên thần kinh để đối phó với nó.
Nhưng điều này sẽ thay đổi khi số lượng tính năng mà AI có tăng lên:
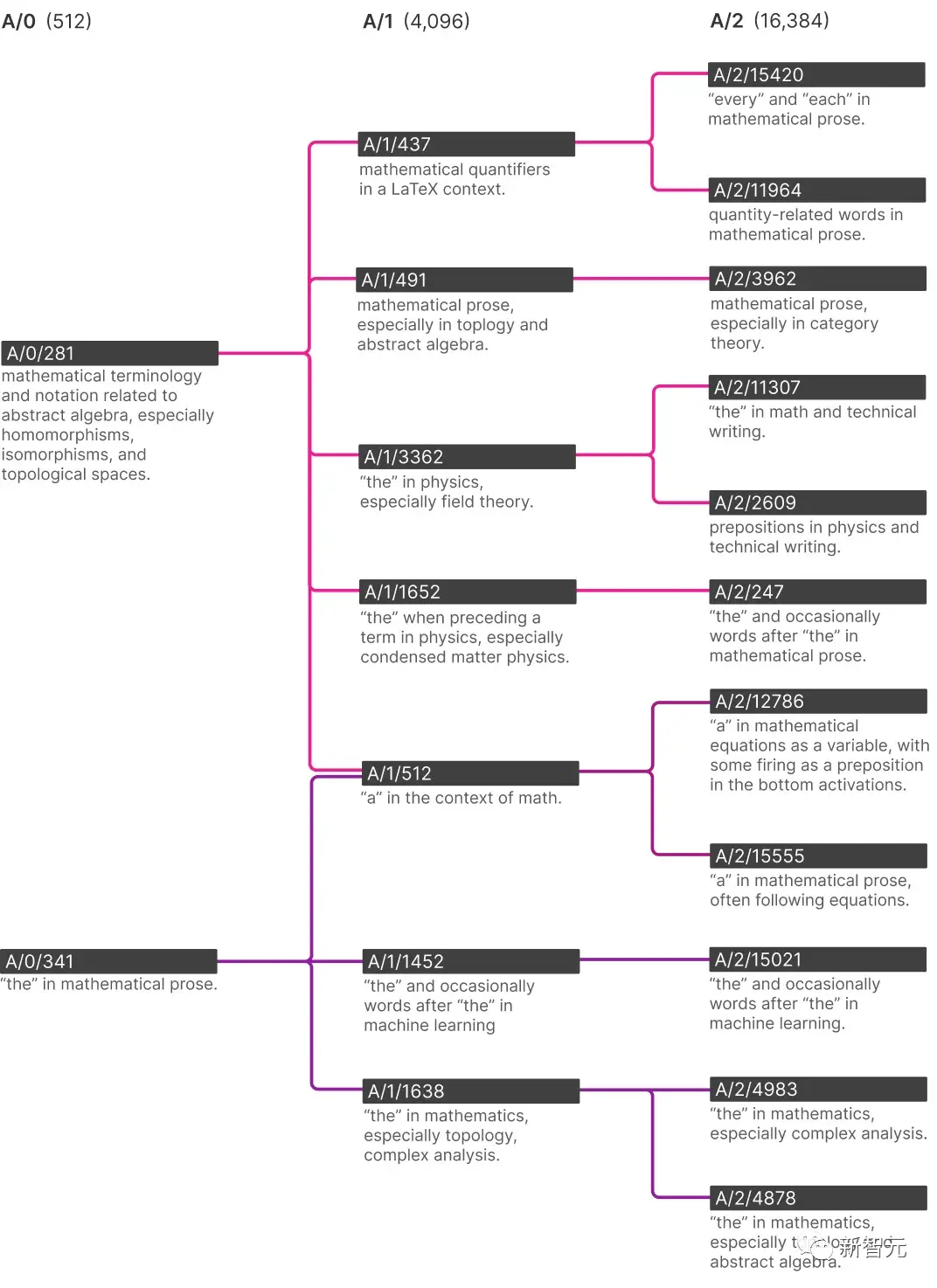 Ở dưới cùng của cây này, bạn có thể thấy cách AI hiểu “the” theo thuật ngữ toán học thay đổi khi nó ngày càng có nhiều đặc điểm hơn.
Ở dưới cùng của cây này, bạn có thể thấy cách AI hiểu “the” theo thuật ngữ toán học thay đổi khi nó ngày càng có nhiều đặc điểm hơn.
Trước hết, tại sao có một tính năng cụ thể của “the” trong một thuật ngữ toán học? Điều này có lẽ là do AI cần dự đoán rằng việc biết một “the” cụ thể nên được theo sau bởi một số từ vựng toán học, chẳng hạn như “tử số” hoặc “cosin”.
Trong số các AI nhỏ nhất được đào tạo bởi các nhà nghiên cứu chỉ với 512 tính năng, chỉ có một tính năng đại diện cho “the”, trong khi AI lớn nhất với 16.384 tính năng đã được chia thành một tính năng đại diện cho “the” trong học máy, một tính năng đại diện cho “the” trong phân tích phức tạp và một tính năng đại diện cho “the” trong cấu trúc liên kết và đại số trừu tượng.
Do đó, nếu hệ thống có thể được nâng cấp lên AI với nhiều tế bào thần kinh mô phỏng hơn, các đặc điểm đại diện cho “Chúa” có thể sẽ chia thành hai - một cho ý nghĩa của “Chúa” trong tôn giáo và một cho “Chúa” trong tên của quái vật.
Sau đó, có thể có Thiên Chúa trong Cơ đốc giáo, Thiên Chúa trong Do Thái giáo, Thiên Chúa trong triết học, v.v.
Nhóm nghiên cứu đã đánh giá khả năng diễn giải chủ quan của 412 nhóm tế bào thần kinh thực và các tế bào thần kinh mô phỏng tương ứng, và thấy rằng khả năng giải thích của các tế bào thần kinh mô phỏng nói chung là tốt:
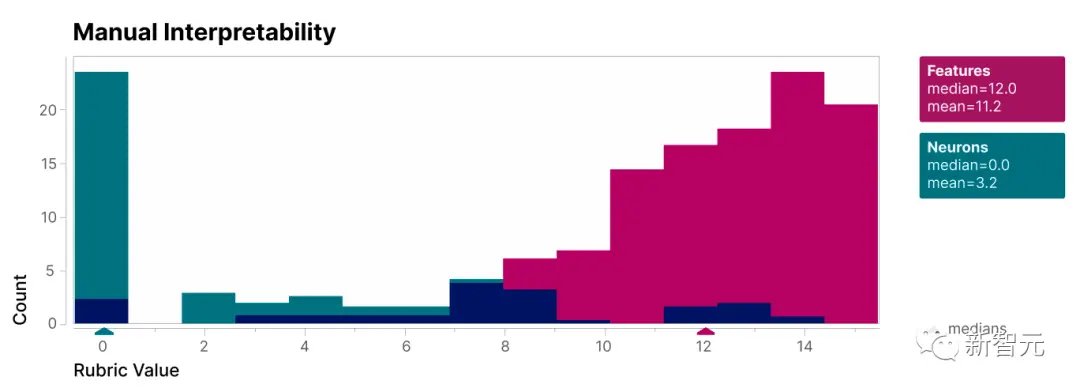 Một số tính năng, chẳng hạn như tính năng có nghĩa là “Chúa”, được sử dụng cho các khái niệm cụ thể.
Một số tính năng, chẳng hạn như tính năng có nghĩa là “Chúa”, được sử dụng cho các khái niệm cụ thể.
Nhiều tính năng có khả năng diễn giải cao khác, bao gồm một số tính năng dễ hiểu nhất, là “định dạng” được sử dụng để biểu diễn văn bản, chẳng hạn như chữ hoa hoặc chữ thường, tiếng Anh hoặc bảng chữ cái khác, v.v.
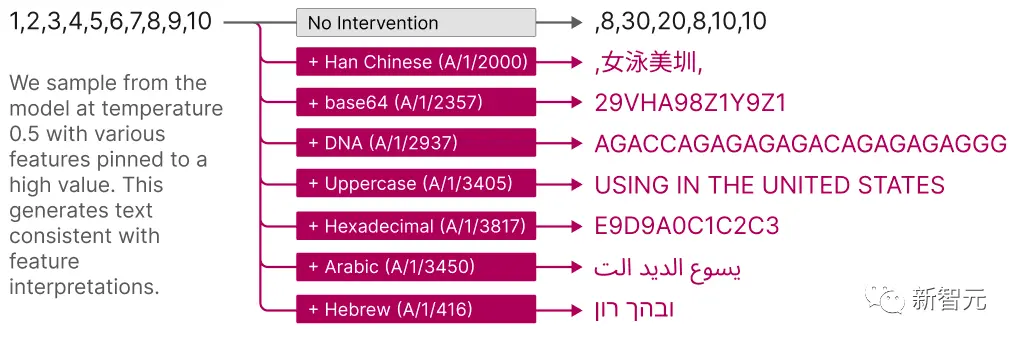 Những tính năng này phổ biến như thế nào? Đó là, nếu bạn đào tạo hai AI 4096 tính năng khác nhau trên cùng một dữ liệu văn bản, chúng sẽ có hầu hết các tính năng 4096 giống nhau? Liệu tất cả họ có những đặc điểm nào đó đại diện cho “Đức Chúa Trời” không?
Những tính năng này phổ biến như thế nào? Đó là, nếu bạn đào tạo hai AI 4096 tính năng khác nhau trên cùng một dữ liệu văn bản, chúng sẽ có hầu hết các tính năng 4096 giống nhau? Liệu tất cả họ có những đặc điểm nào đó đại diện cho “Đức Chúa Trời” không?
Hay AI đầu tiên sẽ đặt “Chúa” và “Godzilla” lại với nhau, và AI thứ hai sẽ tách chúng ra? AI thứ hai sẽ không có tính năng “Chúa” nào cả, mà thay vào đó sử dụng không gian đó để lưu trữ một số khái niệm khác mà AI đầu tiên sẽ không thể hiểu được?
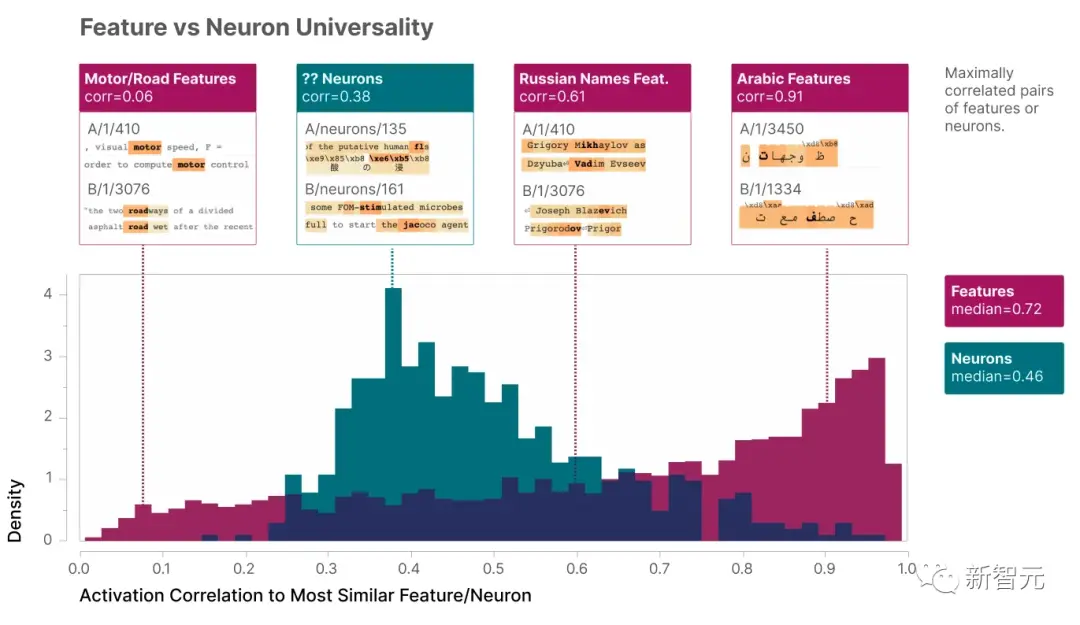
Nhóm nghiên cứu đã thử nghiệm nó và thấy rằng hai mô hình AI của họ rất giống nhau!
Trung bình, nếu có một tính năng trong mô hình đầu tiên, tính năng tương tự nhất trong mô hình thứ hai sẽ có mối tương quan trung bình là 0, 72.
**Đã thấy linh hồn của AI **
Tiếp theo là gì?
Vào tháng 5 năm nay, OpenAI đã cố gắng để GPT-4 (rất lớn) hiểu GPT-2 (rất nhỏ). Họ đã yêu cầu GPT-4 kiểm tra 307.200 tế bào thần kinh của GPT-2 và báo cáo những gì nó tìm thấy.
GPT-4 đã tìm thấy một loạt các kết quả thú vị và một loạt các điều vô nghĩa ngẫu nhiên vì họ chưa thành thạo nghệ thuật chiếu các tế bào thần kinh thực sự lên các tế bào thần kinh mô phỏng và phân tích các tế bào thần kinh mô phỏng.
Mặc dù kết quả không rõ ràng, nhưng đó thực sự là một nỗ lực rất tham vọng.
Không giống như AI này trong bài viết giải thích của Anthropic, GPT-2 là một AI thực sự (mặc dù rất nhỏ) cũng đã gây ấn tượng với công chúng.
Nhưng mục tiêu cuối cùng của nghiên cứu là có thể giải thích các hệ thống AI chính thống.
Nhóm giải thích của Anthropic thừa nhận rằng họ chưa làm điều này, chủ yếu vì một số lý do:
Trước hết, mở rộng quy mô bộ mã hóa tự động là một điều khó thực hiện. Để giải thích một hệ thống như GPT-4 (hoặc hệ thống tương đương của Anthropic, Claude), bạn cần một AI thông dịch có cùng kích thước.
Nhưng đào tạo AI ở quy mô này đòi hỏi sức mạnh tính toán và hỗ trợ tài chính rất lớn.
Thứ hai, khả năng mở rộng của phiên dịch cũng là một vấn đề.
Ngay cả khi chúng tôi tìm thấy tất cả các tế bào thần kinh mô phỏng về Chúa, Godzilla và mọi thứ khác và vẽ một sơ đồ khổng lồ về cách chúng được kết nối.
Các nhà nghiên cứu vẫn cần trả lời các câu hỏi phức tạp hơn và việc giải quyết chúng đòi hỏi các tương tác phức tạp liên quan đến hàng triệu tính năng và kết nối.
Vì vậy, cần phải có một số quy trình tự động, một số loại lớn hơn “hãy để GPT-4 cho chúng tôi biết GPT-2 đang làm gì”.
Cuối cùng, tất cả những điều này nói lên điều gì để hiểu bộ não con người?
Con người cũng sử dụng mạng lưới thần kinh để suy luận và xử lý các khái niệm.
Có rất nhiều tế bào thần kinh trong não người, và điều này giống như GPT-4.
Dữ liệu có sẵn cho con người cũng rất thưa thớt – có nhiều khái niệm (như mực) hiếm khi xuất hiện trong cuộc sống hàng ngày.
Có phải chúng ta cũng đang bắt chước một bộ não lớn hơn?
Đây vẫn là một lĩnh vực nghiên cứu rất mới, nhưng đã có một số phát hiện sơ bộ cho thấy các tế bào thần kinh trong vỏ não thị giác của con người mã hóa các tính năng theo một số cách siêu cục bộ, tương tự như các mẫu quan sát được trong các mô hình AI.
Tài nguyên:
