
Hệ thống ghi nhớ AI MemPalace do Milla Jovovich tham gia phát triển tuyên bố đã đạt điểm tối đa trong các bài kiểm thử và nhanh chóng bùng nổ phổ biến, nhưng cộng đồng lại “đá” lại, cáo buộc bài test có gian lận và dữ liệu bị gây hiểu nhầm. Thực nghiệm phát hiện hiệu quả bị thổi phồng và có rất nhiều lỗi; nhóm phát triển đã thừa nhận những thiếu sót và đang tiến hành khắc phục.
Milla Jovovich xây dựng AI “Cung điện trí nhớ”, thu hút sự chú ý từ bên ngoài
Hôm qua (4/7), trong cộng đồng AI có một tin nóng lớn: nữ minh tinh Hollywood nổi tiếng với Resident Evil và The Fifth Element, Milla Jovovich (Milla Jovovich), cùng với nhà phát triển Ben Sigman đã dùng Claude Code để hỗ trợ phát triển một hệ thống trí nhớ AI mã nguồn mở tên là “MemPalace”.
Trong lúc đó, câu chuyện “ngôi sao Hollywood giao thoa sang làm dự án điểm tối đa” nhanh chóng lan truyền; đến nay MemPalace trên GitHub cũng đã nhận được hơn 20k lượt sao, nhưng rất nhanh đã khiến cộng đồng nhà phát triển nghi ngờ: thực sự có năng lực hay chỉ là PR thổi phồng?
Trước hết, hãy nói động cơ khiến MemPalace ra đời: tài liệu chính thức cho biết họ muốn giải quyết tình trạng các hệ thống AI hiện tại thường làm nội dung hội thoại giữa người dùng và AI, quá trình ra quyết định, cùng với việc thảo luận cấu trúc sẽ biến mất sau khi kết thúc phiên làm việc, dẫn đến giới hạn khiến công sức trong vài tháng bị giảm về 0.
Để giải quyết vấn đề này, MemPalace sử dụng cấu trúc không gian để lưu trí nhớ, phân loại thông tin rõ ràng vào các “cánh” đại diện cho cá nhân hoặc dự án, cùng với cấu trúc ở các cấp độ khác nhau như hành lang, phòng và ngăn kéo, đồng thời giữ nguyên nội dung hội thoại gốc để phục vụ truy hồi ngữ nghĩa về sau.
Nhóm phát triển khẳng định rằng, MemPalace đạt thành tích 100% trong bộ tiêu chí đánh giá trí nhớ dài hạn LongMemEval, và đạt tỷ lệ chính xác 96,6% mà không hề gọi bất kỳ API bên ngoài nào. Hơn nữa, nó có thể chạy hoàn toàn tại chỗ (local), không cần đăng ký dịch vụ đám mây, và tích hợp một hệ thống phương ngữ AAAK được quảng bố có thể nén không mất mát tới 30 lần.
Nguồn ảnh: GitHub Nữ minh tinh phim Hollywood Milla Jovovich xây dựng “cung điện trí nhớ” AI, thu hút sự chú ý từ bên ngoài
Ngành cùng cộng đồng đồng loạt chất vấn, bài test và cách quảng bá có nhiều điểm sai
Tuy nhiên, thành tích “điểm tối đa” 100% trong LongMemEval mà MemPalace công bố nhanh chóng bị cộng đồng trong ngành nghi ngờ.
PenfieldLabs, cũng là công ty sản xuất hệ thống ghi nhớ AI, cho biết MemPalace tuyên bố đạt điểm tối đa trong bộ dữ liệu LoCoMo, điều này toán học là không thể xảy ra, vì đáp án chuẩn của bộ dữ liệu này ngay bản thân nó đã chứa 99 lỗi.
PenfieldLabs phân tích và phát hiện rằng thành tích 100% của MemPalace đến từ việc đặt số lần truy hồi là 50 lần, nhưng số lượng “giai đoạn” cao nhất của đoạn hội thoại trong tập kiểm thử chỉ có 32 lần; điều này có nghĩa là hệ thống đã bỏ qua trực tiếp giai đoạn truy hồi, giao toàn bộ dữ liệu cho mô hình AI để đọc.
Liên quan đến thành tích 100% trong LongMemEval, nhóm phát triển bị phát hiện là đã nhắm vào 3 vấn đề cụ thể, phát sinh sai trong quá trình phát triển; họ viết mã sửa chữa riêng, cho thấy nghi ngờ nhắm vào việc gian lận trong tập kiểm thử.

Nguồn ảnh: Reddit PenfieldLabs trong ngành chỉ ra rằng MemPalace tuyên bố đạt điểm tối đa trong bộ dữ liệu LoCoMo, về mặt toán học là không thể xảy ra
Người dùng GitHub tự test thực tế: bài benchmark có yếu tố gây hiểu nhầm
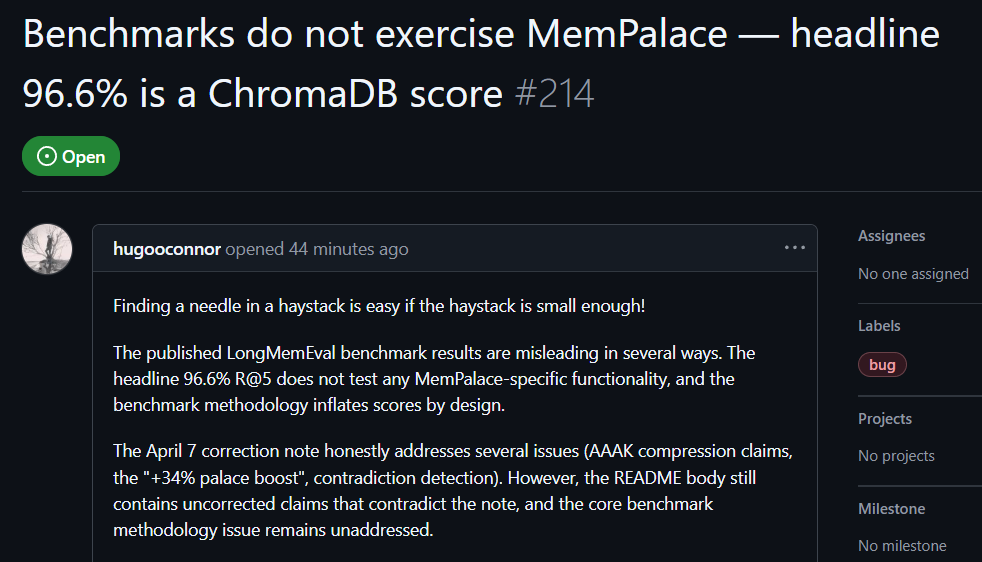
Người dùng GitHub hugooconnor sau khi tự thực nghiệm đã bình luận rằng MemPalace tuyên bố có tới 96,6% độ chính xác truy hồi, nhưng thực tế lại hoàn toàn không hề sử dụng kiến trúc “cung điện trí nhớ” mà MemPalace quảng bá. hugooconnor cho biết thử nghiệm của họ chỉ đơn giản là gọi chức năng mặc định của cơ sở dữ liệu lớp dưới ChromaDB, hoàn toàn không liên quan đến logic phân loại theo các “cánh”, “phòng” hoặc “ngăn kéo” mà dự án nhấn mạnh.
Sau khi thử nghiệm, hugooconnor phát hiện rằng khi hệ thống thật sự bật logic phân loại riêng của những “cung điện trí nhớ” này, hiệu suất truy hồi lại suy giảm. Ví dụ, ở chế độ phòng (room), độ chính xác giảm xuống 89,4%; và sau khi bật công nghệ nén AAAK thì độ chính xác còn giảm thêm xuống 84,2%, cả hai đều thấp hơn so với hiệu suất của cơ sở dữ liệu mặc định.
hugooconnor cũng chỉ trích phương pháp thử nghiệm: môi trường kiểm thử của MemPalace cố tình thu hẹp phạm vi truy hồi của mỗi câu hỏi xuống khoảng 50 giai đoạn hội thoại, khiến việc tìm đáp án trong một bộ mẫu cực nhỏ trở nên quá dễ dàng.
Nếu mở rộng phạm vi lên hơn 19.000 giai đoạn hội thoại trong tình huống thực tế, thì độ chính xác của tìm kiếm từ khóa truyền thống sẽ giảm mạnh xuống 30%, cho thấy cách thử nghiệm hiện tại của MemPalace đang che giấu “bài toán tìm kiếm” khó khăn ngoài đời.
Nguồn ảnh: GitHub Người dùng GitHub tự thực nghiệm cho thấy bài benchmark của MemPalace có yếu tố gây hiểu nhầm
Đồng thời, dù nhóm phát triển đã công bố tuyên bố hiệu chỉnh, thừa nhận rằng công nghệ AAAK thực sự là nén có mất mát và cam kết sẽ dựa theo những phản bác nghiêm khắc của cộng đồng để sửa tài liệu và thiết kế hệ thống. Nhưng tài liệu mô tả chính của dự án vẫn giữ lại nhiều tuyên bố phóng đại chưa được sửa, bao gồm các cáo buộc “nén không mất mát 30 lần” và “tăng 34% truy hồi”, và các biểu đồ so sánh với đối thủ khác cũng hoàn toàn thiếu nguồn xuất xứ.
Mã nguồn gốc của MemPalace đối mặt nhiều lỗi Bug
Khi ngày càng nhiều nhà phát triển tải về để thử nghiệm, hiện tại trên nền tảng GitHub xuất hiện rất nhiều báo cáo lỗi liên quan đến mã nguồn MemPalace.
Người dùng cktang88 liệt kê nhiều sai sót nghiêm trọng, bao gồm lệnh nén không hoạt động và gây sập hệ thống, lỗi trong logic tính toán số lượng từ của bản tóm tắt, dữ liệu thống kê khi “đào” phòng không chính xác, cũng như việc máy chủ mỗi lần gọi lại sẽ nạp toàn bộ dữ liệu chú giải vào bộ nhớ (RAM), gây ra vấn đề tiêu thụ tài nguyên nghiêm trọng.
Những vấn đề khác được chỉ ra còn gồm việc hệ thống tự động ghi tên người thân của nhà phát triển vào tệp cấu hình mặc định, và tồn tại giới hạn hiển thị bắt buộc khi tra trạng thái, lên tới 20kản ghi dữ liệu.
Đối với các vấn đề này, cộng đồng mã nguồn mở đã bắt đầu tích cực khắc phục. Người dùng adv3nt3 đã gửi nhiều yêu cầusửa chữa, bao gồm sửa số liệu thống kê khi đào, loại bỏ tên người thân mặc định, và trì hoãn thời gian khởi tạo việc khởi tạo sơ đồ tri thức (knowledge graph). Nhóm phát triển sau đó cũng thừa nhận các lỗi này, đang dần giải quyết các vấn đề trong mã thông qua sự phối hợp của cộng đồng.
Milla Jovovich Vibe Coding rất cool, nhưng cách marketing thì không cool
Đối với dự án MemPalace, người dùng Hacker News darkhanakh đưa ra một kết luận: MemPalace tạo cảm giác như OpenClaw, tức là thao túng một cách nhân tạo kết quả benchmark để nó trông như hoàn hảo không tì vết, rồi đóng gói nó thành một bước đột phá lớn để đi quảng bá.
Ông ấy cho rằng công nghệ tầng nền của MemPalace có thể đúng là thú vị, nhưng trong bối cảnh phương pháp thử nghiệm có những điểm sai như vậy, lại còn dùng thông điệp “điểm công khai cao nhất trong lịch sử” để quảng cáo thì không thật sự thỏa đáng; “Tuy nhiên, chuyện Milla Jovovich đang chơi Vibe Coding, tôi nghĩ vẫn khá là cool.”
Đọc thêm:
AI viết code xảy ra sự cố! Ứng dụng “惜食獵人” của hàng tươi sống siêu thị gặp vấn đề an ninh, GPS trong nhà để lộ toàn bộ
