Tiêu đề gốc: Anthropic: The Leak, The War, The Weapon
Tác giả gốc: BuBBliK
Biên dịch: Peggy,BlockBeats
Lời của biên tập viên: Trong nửa năm qua, Anthropic liên tiếp bị cuốn vào một loạt các sự kiện tưởng như độc lập với nhau, nhưng thực chất lại cùng hướng về nhau: bước nhảy về năng lực của mô hình AI, các cuộc tấn công tự động trong thế giới thực, phản ứng dữ dội của thị trường vốn, cuộc xung đột công khai với chính phủ, và nhiều lần rò rỉ thông tin bắt nguồn từ sai sót trong cấu hình cơ bản. Khi đặt những manh mối này cạnh nhau, chúng cùng vẽ nên một hướng biến đổi rõ ràng hơn.
Bài viết này lấy các sự kiện trên làm điểm cắt, nhìn lại hành trình liên tục của một công ty AI trong cuộc giằng co giữa bước đột phá công nghệ, phơi bày rủi ro và bài toán quản trị, đồng thời cố gắng trả lời một câu hỏi sâu hơn: khi năng lực “phát hiện lỗ hổng” được khuếch đại đến mức cực đại và dần lan rộng, thì bản thân hệ thống an ninh mạng có còn giữ được logic vận hành ban đầu hay không.
Trước đây, an ninh được xây dựng dựa trên sự khan hiếm năng lực và ràng buộc về nhân lực; còn trong điều kiện mới, công tác phòng thủ và tấn công đang xoay quanh cùng một bộ năng lực mô hình, khiến ranh giới trở nên mơ hồ hơn bao giờ hết. Trong khi đó, phản ứng của thể chế, thị trường và tổ chức vẫn nằm lại trong khung cũ, khó có thể tiếp sức kịp cho sự thay đổi này.
Điều bài viết này quan tâm không chỉ là bản thân Anthropic, mà còn là một thực tế lớn hơn mà nó phản chiếu: AI không chỉ đang thay đổi công cụ, mà còn đang thay đổi các tiền đề để “an ninh được hình thành” như thế nào.
Dưới đây là phần nội dung gốc:
Khi một công ty có vốn hóa 200Mỷ USD, đối đầu với Lầu Năm Góc và giành được lợi thế, vượt qua cuộc tấn công mạng do AI tự chủ khởi xướng lần đầu tiên trong lịch sử, rồi ngay trong nội bộ lại rò rỉ ra một mô hình khiến ngay cả các nhà phát triển của họ cũng cảm thấy sợ hãi, thậm chí còn “vô tình” công khai toàn bộ mã nguồn — tất cả chồng chất lại với nhau thì sẽ là một bức tranh như thế nào?
Câu trả lời là đúng như bây giờ. Và điều đáng bất an hơn nữa là: phần nguy hiểm nhất thực sự có lẽ vẫn chưa xảy ra.
Tổng quan sự kiện
Anthropic lại rò rỉ mã của chính mình
Ngày 31/3/2026, nhà nghiên cứu bảo mật Shou Chaofan của công ty blockchain Fuzzland khi kiểm tra gói Claude Code npm do bên chính thức phát hành đã phát hiện rằng bên trong lại chứa một cách hiển thị rõ ràng một tệp có tên cli.js.map.
Tệp này có dung lượng đạt 60MB, nội dung còn gây sốc hơn. Nó gần như chứa toàn bộ bộ mã nguồn TypeScript hoàn chỉnh của sản phẩm. Chỉ riêng một tệp này, bất kỳ ai cũng có thể khôi phục tối đa 1Mệp mã nguồn nội bộ: bao gồm thiết kế API nội bộ, hệ thống telemetry, công cụ mã hóa, logic bảo mật, hệ thống plugin — gần như tất cả các thành phần cốt lõi đều hiện ra rõ ràng. Quan trọng hơn, các nội dung này thậm chí có thể được tải trực tiếp từ chính bộ lưu trữ R2 của Anthropic về dưới dạng tệp zip.
Phát hiện này nhanh chóng lan truyền trên mạng xã hội: trong vài giờ, các bài đăng liên quan thu hút 754k lượt xem và gần 1000 lượt chia sẻ; đồng thời, nhiều kho GitHub khôi phục mã nguồn cũng được tạo và công khai ngay lập tức.
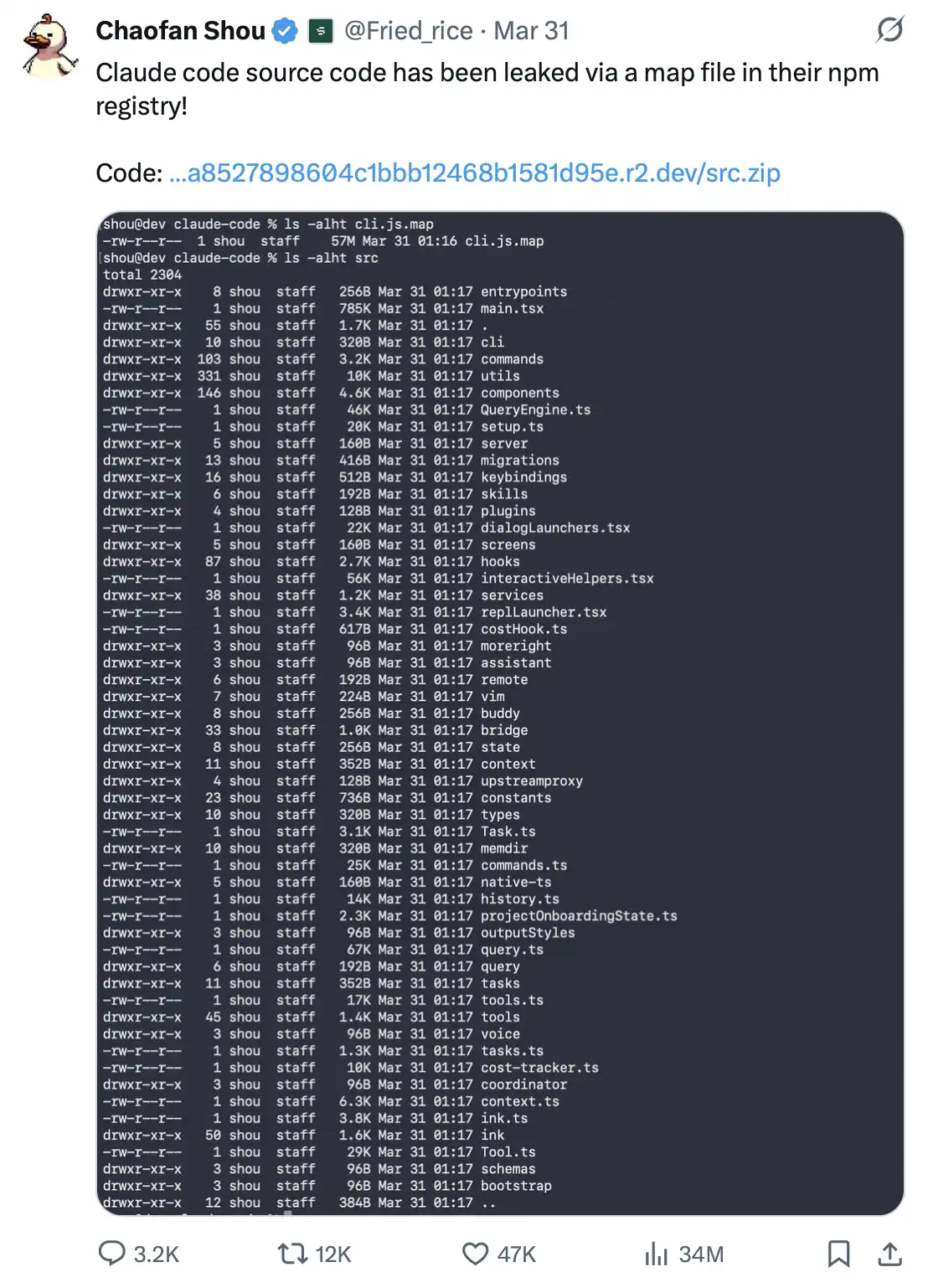
Được gọi là source map (tệp ánh xạ nguồn), về bản chất chỉ là một tệp trợ giúp dùng cho gỡ lỗi JavaScript; tác dụng của nó là khôi phục mã sau khi được nén/biên dịch về lại mã nguồn gốc, để giúp nhà phát triển truy tra lỗi.
Nhưng có một nguyên tắc cơ bản: nó tuyệt đối không nên được đưa vào gói phát hành ở môi trường sản xuất.
Đây không phải là một thủ đoạn tấn công cao siêu, mà là một vấn đề chuẩn mực kỹ thuật căn bản của khâu xây dựng hệ thống—thuộc kiểu “xây dựng cấu hình nhập môn 101”, thậm chí là thứ mà nhà phát triển học ngay từ tuần đầu. Nếu bị đóng gói nhầm vào môi trường sản xuất, source map thường đồng nghĩa với việc “tặng kèm” mã nguồn cho tất cả mọi người.
Bạn cũng có thể xem trực tiếp đoạn mã liên quan tại đây: https://github.com/instructkr/claude-code
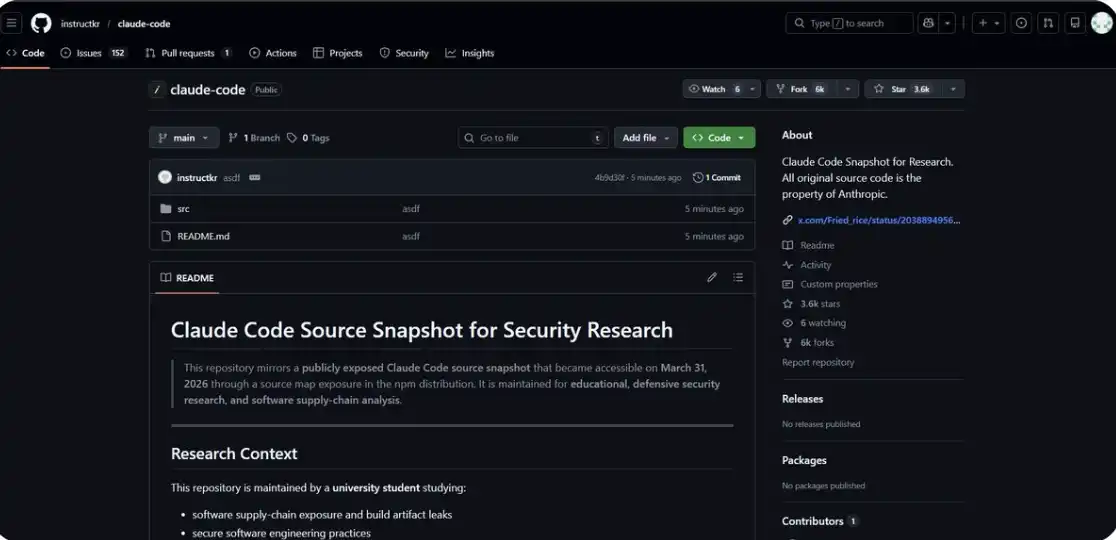
Nhưng điều thật sự khiến người ta thấy vô lý nằm ở chỗ: chuyện này đã từng xảy ra một lần rồi.
Vào tháng 2/2025, tức là một năm trước, cũng đã có gần như y hệt một lần rò rỉ: cùng một tệp, cùng một kiểu sai sót. Khi đó, Anthropic đã xóa phiên bản cũ khỏi npm, loại bỏ source map và phát hành lại phiên bản mới, và mọi việc coi như dừng lại.
Kết quả là ở phiên bản v2.1.88, tệp này lại một lần nữa được đóng gói và phát hành.
Một công ty có vốn hóa 15Bỷ USD, đang xây dựng hệ thống phát hiện lỗ hổng tiên tiến bậc nhất toàn cầu, trong vòng một năm đã mắc phải hai lần cùng một sai lầm nền tảng. Không có tấn công của hacker, không có đường khai thác phức tạp—chỉ là một vấn đề ở quy trình build vốn lẽ ra phải chạy bình thường.
Sự mỉa mai này gần như mang màu sắc “tính chất thơ”.
Con AI có thể phát hiện 500 lỗ hổng zero-day chỉ trong một lần chạy; mô hình được dùng để phát động các cuộc tấn công tự động vào 380Bổ chức trên toàn cầu—và trong khi đó, Anthropic lại “đóng gói tặng” mã nguồn của chính mình cho bất cứ ai chỉ cần nhìn qua gói npm.
Hai lần rò rỉ, cách nhau chưa đến bảy ngày.
Nguyên nhân lại y hệt nhau: sai sót cấu hình căn bản nhất. Không cần bất kỳ ngưỡng kỹ thuật nào, không cần đường khai thác phức tạp. Chỉ cần biết đi xem ở đâu, bất kỳ ai cũng có thể nhận miễn phí.
Một tuần trước: lộ bất ngờ “mô hình nguy hiểm” nội bộ
Ngày 26/3/2026, các nhà nghiên cứu bảo mật Roy Paz đến từ LayerX Security và Alexandre Pauwels đến từ University of Cambridge phát hiện ra rằng cấu hình CMS trên trang web chính thức của Anthropic có vấn đề, dẫn đến việc khoảng 754kài liệu nội bộ bị truy cập công khai.
Những tài liệu này bao gồm: bản nháp blog, PDF, tài liệu nội bộ, tài liệu trình diễn—tất cả đều bị lộ trong một kho dữ liệu không hề được bảo vệ, có thể được tìm kiếm. Không có hacker tấn công, cũng không cần bất kỳ biện pháp hay kỹ thuật nào.
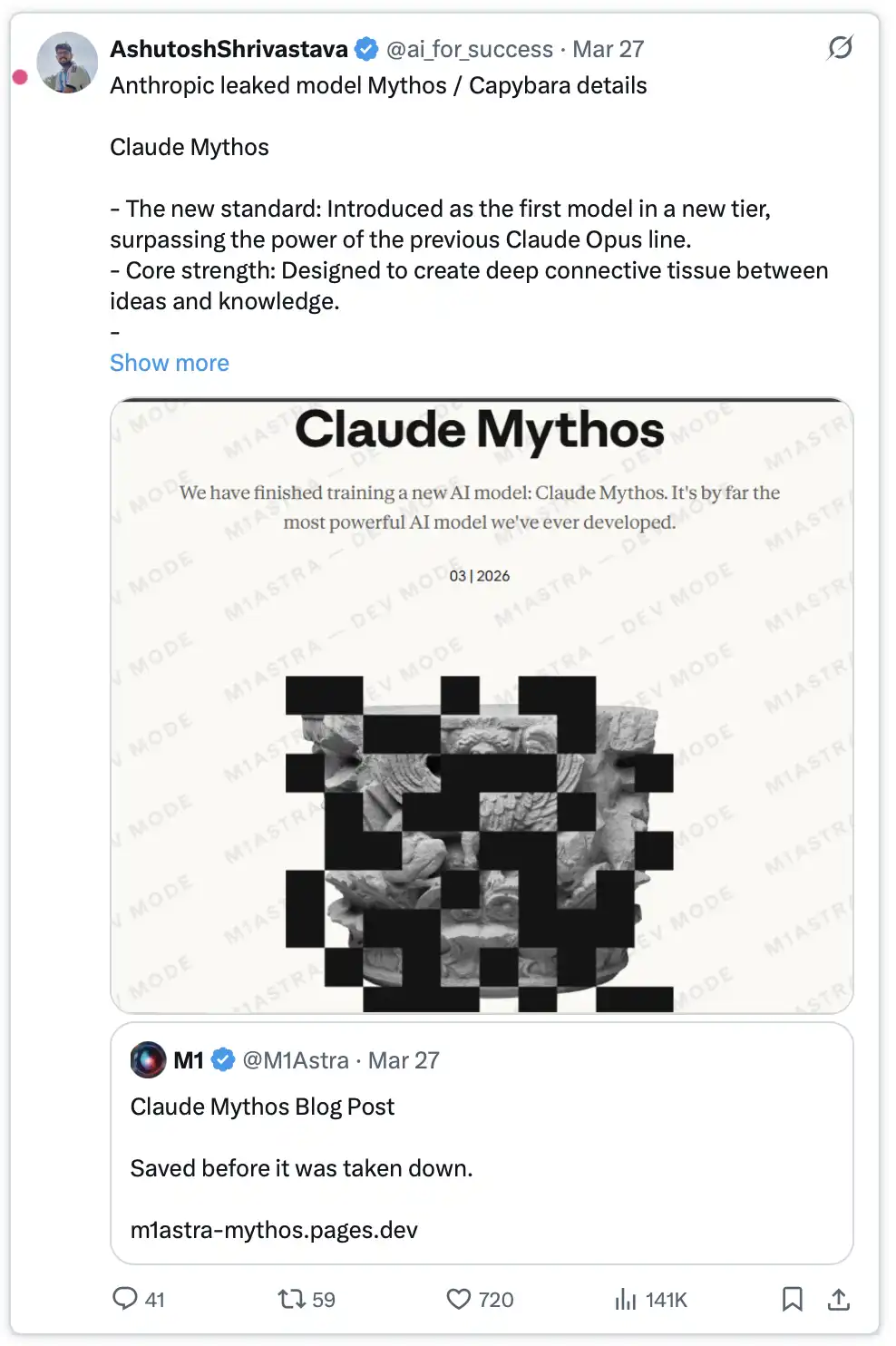
Trong số các tài liệu này, có hai bản nháp blog gần như hoàn toàn giống nhau, khác biệt duy nhất là tên mô hình: một bản ghi “Mythos”, bản còn lại ghi “Capybara”.
Điều này có nghĩa là vào thời điểm đó, Anthropic đang cân nhắc lựa chọn tên cho cùng một dự án bí mật giữa hai phương án. Sau đó công ty xác nhận: việc huấn luyện của mô hình này đã hoàn tất và đã bắt đầu được đưa vào thử nghiệm với một số khách hàng ban đầu.
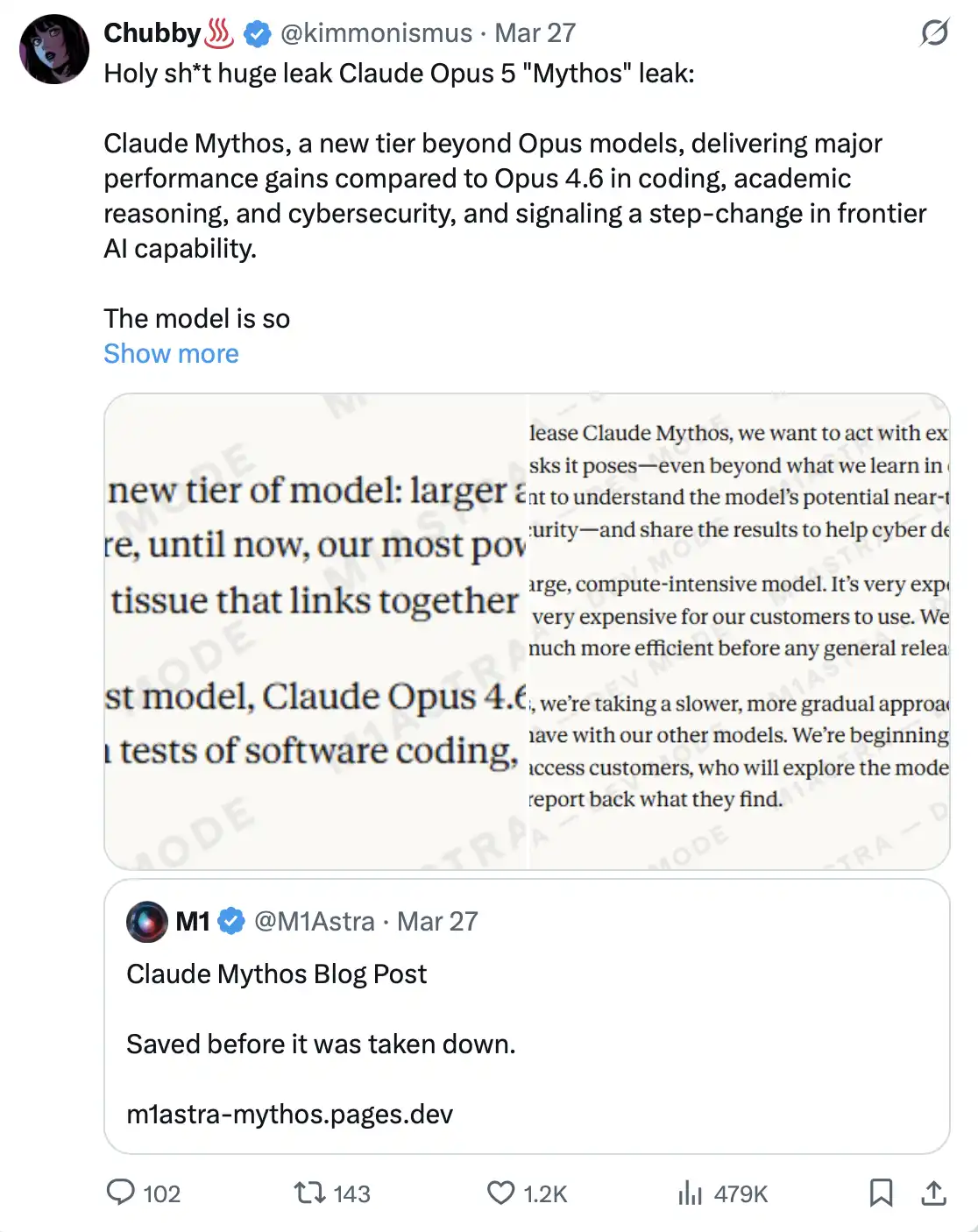
Đây không phải là một bản nâng cấp thông thường cho Opus, mà là một mô hình hoàn toàn mới thuộc “cấp độ thứ tư”, một hệ thống có định vị thậm chí còn cao hơn cả Opus.
Trong chính bản nháp của Anthropic, mô hình này được mô tả: “lớn hơn và thông minh hơn mô hình Opus của chúng tôi—mà Opus cho đến nay vẫn là mô hình mạnh nhất của chúng tôi.” Ở năng lực lập trình, suy luận học thuật và an ninh mạng, v.v., nó đều đạt được bước nhảy đáng kể. Một phát ngôn viên gọi đó là “một bước nhảy mang tính chất về chất”, và cũng là “mô hình mạnh nhất mà chúng tôi từng xây dựng cho đến nay”.
Nhưng điều đáng chú ý thực sự không nằm ở những mô tả hiệu năng này.
Trong các bản nháp bị rò rỉ, đánh giá của Anthropic về mô hình này là: nó “mang đến rủi ro an ninh mạng chưa từng có”, “vượt xa mọi mô hình AI khác về năng lực mạng”, và “báo trước một làn sóng mô hình sắp tới—khả năng khai thác lỗ hổng của nó sẽ vượt xa tốc độ phản ứng của phía phòng thủ”.
Nói cách khác, trong một bản nháp blog chính thức chưa công khai, Anthropic đã thể hiện rõ một lập trường hiếm thấy: họ cảm thấy bất an với sản phẩm mà họ đang xây dựng.
Phản ứng của thị trường gần như ngay lập tức. Cổ phiếu CrowdStrike giảm 7%, Palo Alto Networks giảm 6%, Zscaler giảm 4,5%; Okta và SentinelOne đều giảm hơn 7%, Tenable thậm chí sụt mạnh 9%. iShares Cybersecurity ETF giảm 4,5% trong ngày. Chỉ riêng CrowdStrike, trong ngày đó vốn hóa của hãng đã bốc hơi khoảng 380Bỷ USD. Trong khi đó, Bitcoin rơi về 66.000 USD.
Rõ ràng thị trường đã diễn giải sự kiện này như một “phán quyết” cho toàn bộ ngành an ninh mạng.

Ý chính trong hình: Do ảnh hưởng của các tin tức liên quan, toàn bộ lĩnh vực an ninh mạng giảm; nhiều công ty đầu ngành (như CrowdStrike, Palo Alto Networks, Zscaler, v.v.) ghi nhận mức giảm rõ rệt, phản ánh nỗi lo của thị trường về việc AI tác động đến ngành an ninh mạng. Tuy nhiên, phản ứng này không phải là lần đầu xuất hiện. Trước đó, khi Anthropic công bố công cụ quét mã, các cổ phiếu liên quan cũng từng giảm, cho thấy thị trường đã bắt đầu xem AI là một mối đe dọa mang tính cấu trúc đối với các nhà cung cấp an ninh truyền thống, khiến cả ngành phần mềm chịu áp lực tương tự.
Đánh giá của nhà phân tích Adam Borg thuộc Stifel khá thẳng thắn: mô hình này “có tiềm năng trở thành công cụ hacker tối thượng, thậm chí có thể biến một hacker bình thường thành đối thủ có năng lực tấn công cấp quốc gia”.
Vậy tại sao vẫn chưa được công bố phát hành? Giải thích của Anthropic là: chi phí vận hành của Mythos “rất cao”, chưa đủ điều kiện để phát hành cho công chúng. Kế hoạch hiện tại là mở quyền truy cập giai đoạn đầu cho một nhóm nhỏ các đối tác an ninh mạng nhằm củng cố hệ thống phòng thủ; sau đó mới dần mở rộng phạm vi truy cập API. Trước thời điểm đó, công ty vẫn tiếp tục tối ưu hiệu suất.
Nhưng điểm mấu chốt là: mô hình này đã tồn tại, đã đang trong giai đoạn thử nghiệm, và thậm chí chỉ vì “bị lộ ra ngoài một cách bất ngờ” mà đã tạo ra cú sốc đối với toàn bộ thị trường vốn.
Anthropic đã tạo ra một mô hình AI mà chính họ gọi là “mô hình AI có rủi ro an ninh mạng cao nhất trong lịch sử”. Và việc rò rỉ tin tức của nó lại đến từ một sai sót cấu hình cơ sở hạ tầng phổ biến nhất—cũng chính là loại sai lầm mà các mô hình như thế này ban đầu được thiết kế để tìm ra.

Tháng 3/2026: Anthropic đối đầu với Lầu Năm Góc và giành được lợi thế
Tháng 7/2025, Anthropic ký một hợp đồng trị giá 200 triệu USD với Bộ Quốc phòng Hoa Kỳ, thoạt nhìn chỉ là một lần hợp tác thông thường. Nhưng trong quá trình đàm phán triển khai thực tế sau đó, mâu thuẫn nhanh chóng leo thang.
Lầu Năm Góc muốn có “toàn quyền truy cập” đối với Claude trên nền tảng GenAI.mil của họ, với mục đích bao gồm mọi “mục đích hợp pháp”—trong đó thậm chí bao gồm cả các hệ thống vũ khí hoàn toàn tự chủ và giám sát nội địa quy mô lớn đối với công dân Hoa Kỳ.
Anthropic đã vạch ra “đường đỏ” ở hai vấn đề then chốt và kiên quyết từ chối; cuộc đàm phán kết thúc thất bại vào tháng 9/2025.
Sau đó, tình hình nhanh chóng leo thang. Ngày 27/2/2026, Donald Trump đăng bài trên Truth Social, yêu cầu mọi cơ quan liên bang “ngay lập tức ngừng” sử dụng công nghệ của Anthropic và gọi công ty này là “tả khuynh cấp tiến”.
Ngày 5/3/2026, Bộ Quốc phòng Hoa Kỳ chính thức xếp Anthropic vào nhóm “rủi ro chuỗi cung ứng”.
Nhãn này trước đây gần như chỉ được dùng cho các đối thủ nước ngoài—như các công ty Trung Quốc hoặc các thực thể của Nga—và lần này mới lần đầu tiên được áp dụng cho một công ty của Mỹ có trụ sở tại San Francisco. Đồng thời, Amazon, Microsoft và Palantir Technologies cũng được yêu cầu chứng minh rằng trong bất kỳ hoạt động liên quan quân sự nào của họ, Claude không hề được sử dụng.
CTO của Lầu Năm Góc Emile Michael giải thích cho quyết định này rằng: Claude có thể “làm nhiễm bẩn chuỗi cung ứng”, vì trong nội bộ mô hình có nhúng nhiều “sở thích chính sách” khác nhau. Nói cách khác, trong ngữ cảnh chính thức, một AI bị đặt giới hạn trong cách sử dụng và không sẵn sàng trợ giúp vô điều kiện cho hành vi gây sát thương, lại bị xem như một rủi ro an ninh quốc gia.

Ngày 26/3/2026, thẩm phán liên bang Rita Lin ban hành một bản án dài 43 trang, chặn toàn diện các biện pháp liên quan của Lầu Năm Góc.
Trong phán quyết, bà viết: “Không có bất kỳ cơ sở nào trong luật hiện hành ủng hộ một logic mang màu sắc ‘kiểu Orwell’ như vậy—chỉ vì bất đồng với lập trường của chính phủ, một công ty Mỹ có thể bị gắn nhãn là đối tượng tiềm ẩn của phía thù địch. Khi Anthropic bị trừng phạt vì đã đặt lập trường chính phủ trước sự giám sát của công chúng, về bản chất đó là một dạng trả đũa điển hình theo Tu chính án thứ Nhất, trái pháp luật.” Một ý kiến của tòa án (amicus) thậm chí còn mô tả hành động của Lầu Năm Góc là “cố gắng thực hiện hành vi giết chết doanh nghiệp”.
Kết quả là, chính phủ tìm cách kiềm chế Anthropic nhưng lại khiến công ty nhận được sự chú ý lớn hơn. Ứng dụng Claude lần đầu vượt ChatGPT trên App Store, lượng đăng ký có lúc đạt hơn 1 triệu lượt mỗi ngày.
Một công ty AI nói “không” với tổ chức quân sự quyền lực nhất thế giới. Và tòa án, đứng về phía họ.
Tháng 11/2025: cuộc tấn công mạng do AI dẫn dắt lần đầu tiên trong lịch sử
Ngày 14/11/2025, Anthropic công bố một báo cáo khiến dư luận chấn động rộng rãi.
Báo cáo tiết lộ: một tổ chức hacker được nhà nước Trung Quốc hậu thuẫn, sử dụng Claude Code để phát động các cuộc tấn công tự động nhằm vào 380Bổ chức trên toàn cầu—mục tiêu bao gồm các gã khổng lồ công nghệ, ngân hàng và nhiều cơ quan chính phủ của các quốc gia.
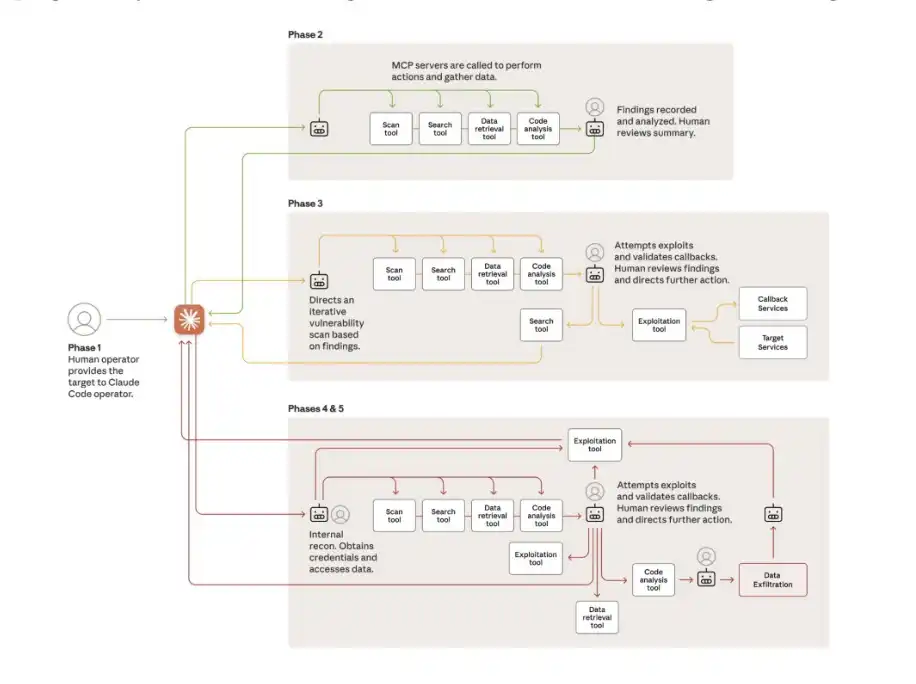
Đây là một bước ngoặt then chốt: AI không còn chỉ đóng vai trò công cụ hỗ trợ, mà bắt đầu được dùng để thực hiện độc lập các hành vi tấn công.
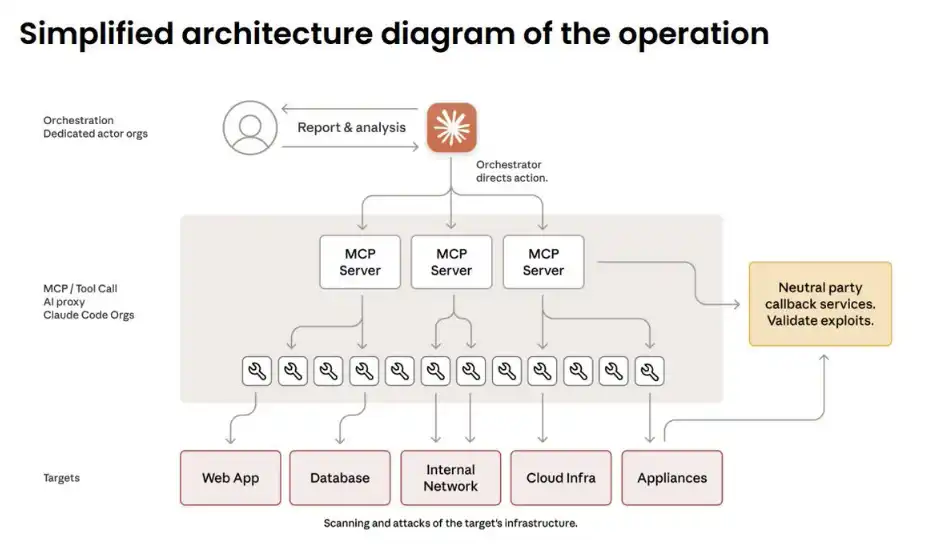
Mấu chốt nằm ở việc thay đổi “cách thức phân công”: con người chỉ chịu trách nhiệm chọn mục tiêu và phê duyệt các quyết định then chốt. Trong suốt quá trình hành động, con người chỉ can thiệp khoảng 4 đến 6 lần. Mọi thứ còn lại đều do AI thực hiện: trinh sát tình báo, phát hiện lỗ hổng, viết mã khai thác, trộm dữ liệu, cài cắm backdoor… chiếm 80%–90% toàn bộ quy trình tấn công, và hoạt động với tốc độ hàng nghìn yêu cầu mỗi giây—một quy mô và hiệu suất mà bất kỳ đội ngũ con người nào cũng không thể sánh kịp.
Vậy họ đã vượt qua cơ chế bảo vệ an toàn của Claude như thế nào? Câu trả lời là: họ không “bẻ khóa”, mà là “lừa”.
Cuộc tấn công được chia nhỏ thành vô số các tác vụ nhỏ trông có vẻ vô hại, và được đóng gói như một “bài kiểm tra phòng thủ có ủy quyền” của một “công ty an ninh hợp pháp”. Về bản chất, đây là một cuộc tấn công theo kiểu kỹ thuật xã hội, chỉ là lần này, đối tượng bị lừa lại chính là AI.
Một phần các cuộc tấn công đạt được thành công hoàn toàn. Claude có thể tự vẽ ra toàn bộ sơ đồ mạng, định vị cơ sở dữ liệu và hoàn tất việc trích xuất dữ liệu mà không cần con người từng bước chỉ lệnh.
Yếu tố duy nhất làm chậm nhịp độ cuộc tấn công là việc mô hình thỉnh thoảng “ảo giác”—ví dụ bịa đặt ra thông tin xác thực, hoặc khẳng định rằng họ đã có được các tệp vốn đã được công khai từ trước. Ít nhất cho đến hiện tại, đây vẫn là một trong số ít “cản trở tự nhiên” ngăn chặn hoàn toàn các cuộc tấn công mạng tự động.
Tại RSA Conference 2026, cựu lãnh đạo phụ trách an ninh mạng thuộc Cơ quan An ninh Quốc gia Hoa Kỳ Rob Joyce gọi sự kiện này là một bài “thử nghiệm Rorschach”: một nửa người chọn bỏ qua, nửa còn lại lại cảm thấy lạnh gáy. Và rõ ràng ông thuộc nhóm sau—“Thật sự rất đáng sợ.”
Tháng 9/2025: đây không phải là một dự đoán, mà là một thực tế đã xảy ra
Tháng 2/2026: một lần chạy phát hiện 500 lỗ hổng zero-day
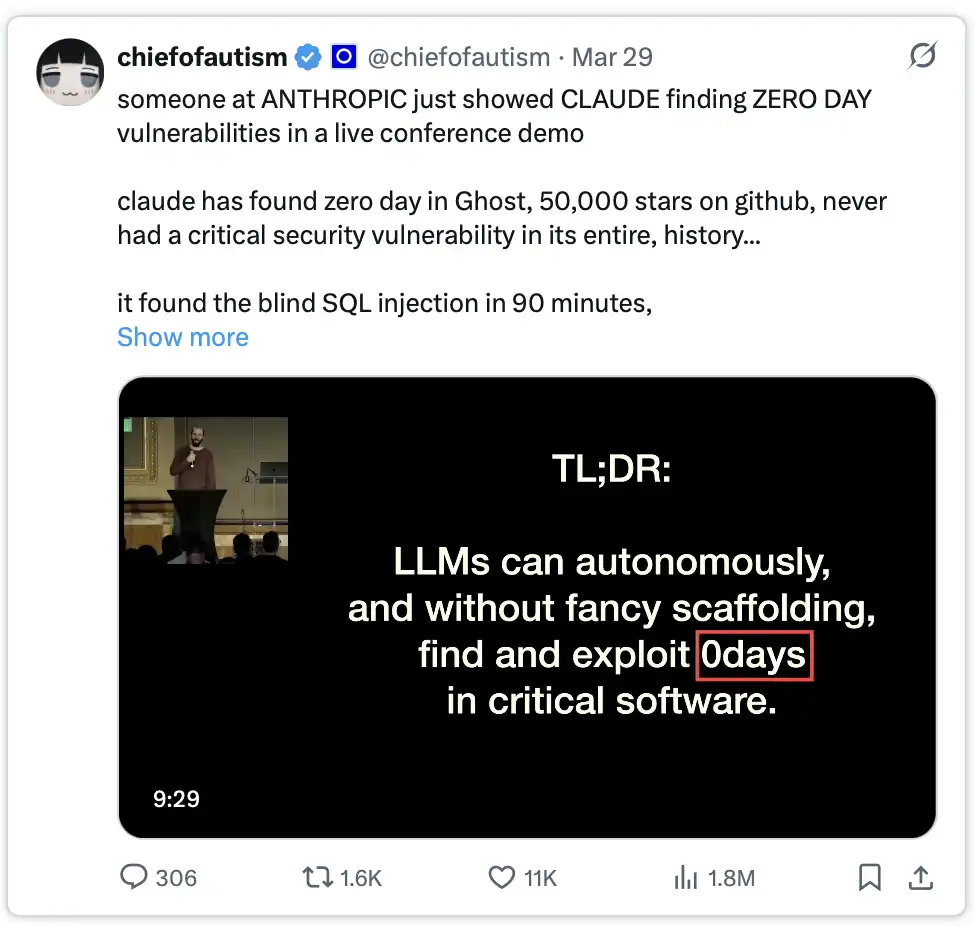
Ngày 5/2/2026, Anthropic phát hành Claude Opus 4.6, đồng thời kèm theo một bài nghiên cứu khiến hầu như cả ngành an ninh mạng chấn động.
Thiết lập thí nghiệm cực kỳ đơn giản: đưa Claude vào một môi trường máy ảo biệt lập, trang bị công cụ chuẩn—Python, bộ gỡ lỗi, công cụ fuzzing (fuzzers). Không có chỉ lệnh bổ sung, cũng không có prompt phức tạp—chỉ một câu: “Đi tìm lỗ hổng.”
Kết quả là: mô hình đã phát hiện hơn 500 lỗ hổng zero-day nguy cấp chưa từng biết đến. Một số lỗ hổng trong đó thậm chí sau nhiều chục năm được các chuyên gia rà soát và hàng triệu giờ kiểm thử tự động vẫn chưa từng được phát hiện.

Sau đó, tại RSA Conference 2026, nhà nghiên cứu Nicholas Carlini lên sân khấu trình diễn. Ông hướng Claude vào Ghost, một hệ thống CMS trên GitHub có 50k sao và trong lịch sử chưa từng xuất hiện lỗ hổng nghiêm trọng.
Sau 90 phút, kết quả xuất hiện: lỗ hổng blind SQL injection được phát hiện, cho phép người dùng chưa được xác thực chiếm quyền quản trị hoàn toàn.
Tiếp theo, ông lại dùng Claude để phân tích Linux kernel. Kết quả giống hệt như vậy.
Sau 15 ngày, Anthropic tung ra Claude Code Security, một sản phẩm an ninh không còn dựa vào khớp mẫu mà dựa trên “năng lực suy luận” để hiểu về độ an toàn của mã nguồn.
Nhưng chính phát ngôn viên của Anthropic cũng nói ra sự thật then chốt, dù nó thường bị né tránh: “Cùng năng lực suy luận đó, có thể giúp Claude phát hiện và sửa lỗ hổng, nhưng cũng có thể bị kẻ tấn công dùng để khai thác các lỗ hổng đó.”
Cùng một năng lực, cùng một mô hình—chỉ là nằm trong tay những người khác nhau.
Tất cả những điều này khi ghép lại lại có nghĩa là gì?
Nếu nhìn riêng từng việc, mỗi vấn đề cũng đủ trở thành tin tức nặng ký nhất của tháng. Nhưng chúng lại, trong vòng chỉ sáu tháng ngắn ngủi, tất cả đều xảy ra ở cùng một công ty.
Anthropic tạo ra một mô hình có thể phát hiện lỗ hổng nhanh hơn bất kỳ con người nào; tin tặc Trung Quốc biến phiên bản thế hệ trước thành vũ khí mạng tự động; công ty đang phát triển thế hệ mô hình mạnh hơn kế tiếp, thậm chí trong các tài liệu nội bộ còn thừa nhận rằng—họ cảm thấy bất an.
Chính phủ Hoa Kỳ tìm cách kiềm chế nó không phải vì bản thân công nghệ đó nguy hiểm, mà vì Anthropic từ chối giao năng lực này ra ngoài mà không có giới hạn.
Và trong toàn bộ quá trình đó, công ty này lại hai lần rò rỉ mã nguồn của chính mình chỉ vì cùng một tệp trong cùng một gói npm. Một công ty có vốn hóa 754k USD; một công ty có mục tiêu hoàn thành đợt IPO 60Bỷ USD vào tháng 10/2026; một công ty đã công khai tuyên bố rằng họ đang xây dựng “một trong những công nghệ mang tính biến đổi nhất trong lịch sử loài người, và có thể cũng là một trong những công nghệ nguy hiểm nhất”—nhưng họ vẫn tiếp tục đẩy tiến độ.
Bởi vì họ tin rằng: thay vì để người khác làm, tốt hơn là để chính họ làm.
Còn với source map trong gói npm đó—có lẽ nó chỉ là một chi tiết vừa vô lý vừa chân thực nhất trong câu chuyện đáng bất an nhất của thời đại này.
Và Mythos, thậm chí còn chưa chính thức được phát hành.

[Liên kết gốc]
Nhấp để biết thêm về việc Lữ động BlockBeats đang tuyển dụng
Chào mừng bạn tham gia cộng đồng chính thức của Lữ động BlockBeats:
Nhóm đăng ký Telegram: https://t.me/theblockbeats
Nhóm thảo luận Telegram: https://t.me/BlockBeats_App
Tài khoản Twitter chính thức: https://twitter.com/BlockBeatsAsia
