Первоисточник: New Zhiyuan
 Источник изображения: Generated by Unbounded AI
Источник изображения: Generated by Unbounded AI
Для того, чтобы распаковать «черный ящик» больших моделей, команда Anthropic explainability опубликовала статью, описывающую, как они могут обучить новую модель понимать простую модель.
Исследование, опубликованное Anthropic, утверждает, что способно увидеть душу искусственного интеллекта. Выглядит это так:
 Адрес:
Адрес:
По словам исследователей, новая модель может точно предсказывать и понимать принцип работы и механизм состава нейронов в исходной модели.
Команда объяснимости Anthropic недавно объявила, что они успешно разложили абстрактное многомерное пространство признаков в смоделированной системе искусственного интеллекта.
Создайте объяснимый ИИ, чтобы понять «черный ящик ИИ»
Исследователи сначала обучили очень простой ИИ из 512 нейронов предсказывать текст, а затем обучили другой ИИ, называемый «автоэнкодером», предсказывать паттерн активации первого ИИ.
Автоэнкодеров просят сконструировать набор признаков (соответствующих количеству нейронов в ИИ более высокой размерности) и предсказать, как эти признаки будут отображаться с нейронами в реальном ИИ.
Было обнаружено, что в то время как нейроны в исходном ИИ было нелегко понять, смоделированные нейроны в новом ИИ (т.е. «признаки») были моносемиными, и каждая функция представляла собой определенную концепцию или функцию.
Например, черта #2663 представляет собой концепцию «Бог».
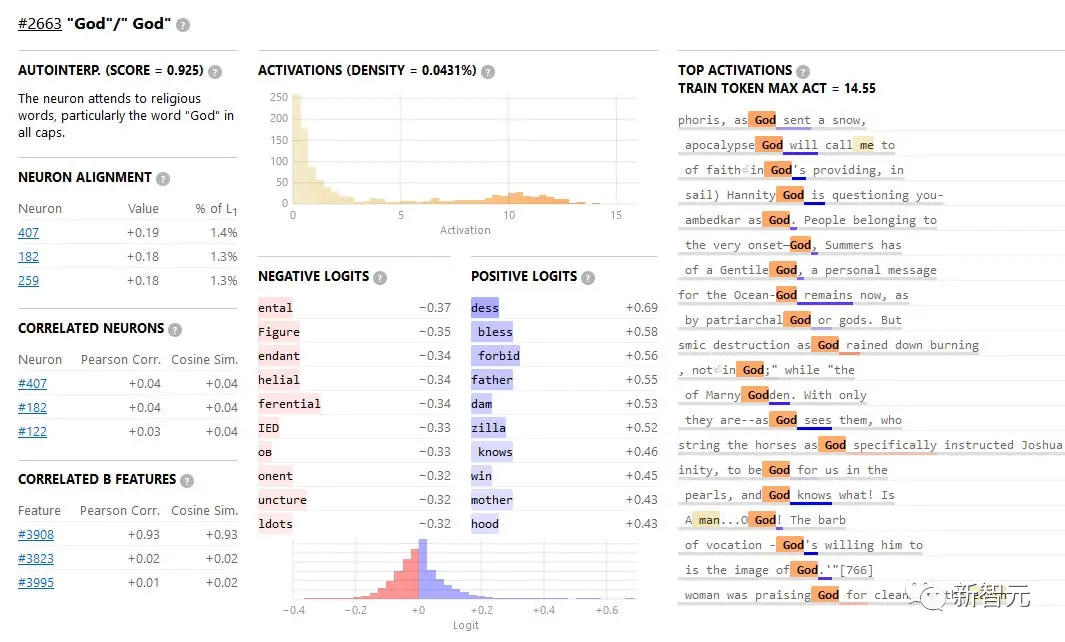 Самая сильная из тренировочных фраз для его активации взята из записи Иосифа Флавия, которая гласит: «Когда метель обрушивается на Бога, он идет в Сепфорис».
Самая сильная из тренировочных фраз для его активации взята из записи Иосифа Флавия, которая гласит: «Когда метель обрушивается на Бога, он идет в Сепфорис».
Вы можете видеть, что активации наверху связаны с различными способами использования слова «Бог».
Этот смоделированный нейрон, по-видимому, состоит из набора реальных нейронов, включая 407, 182 и 259.
Сами по себе эти реальные нейроны имеют мало общего с «Богом», например, Neuron 407 реагирует в первую очередь на неанглийский (особенно ударные латинские буквы) и нестандартный текст (например, HTML-теги).
Но на уровне фичи все в порядке, и когда функция 2663 активирована, она увеличивает вероятность появления в тексте «благословить», «запретить», «черт» или «-зилла».
Искусственный интеллект не отличает понятие «Бог» от «Бога» в имени монстра. Это может быть связано с тем, что импровизированный ИИ не имеет достаточно нейронных ресурсов, чтобы справиться с этим.
Но это будет меняться по мере увеличения количества функций, которыми обладает ИИ:
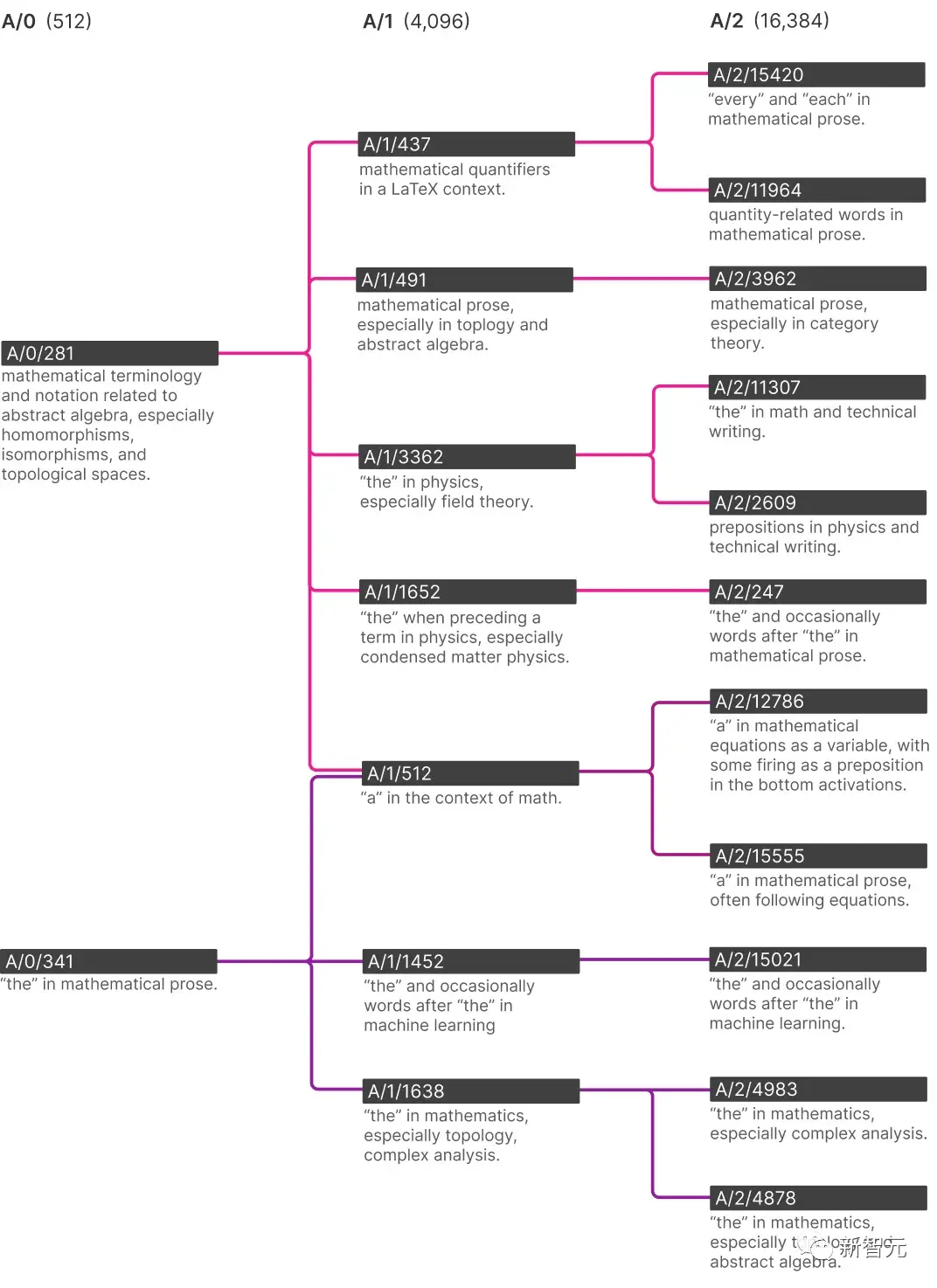 В нижней части этого дерева вы можете увидеть, как ИИ понимает изменения в математических терминах по мере того, как у него появляется все больше и больше характеристик.
В нижней части этого дерева вы можете увидеть, как ИИ понимает изменения в математических терминах по мере того, как у него появляется все больше и больше характеристик.
Прежде всего, почему в математическом термине есть специфическая особенность “the”? Вероятно, это связано с необходимостью ИИ предсказывать, что за знанием конкретного «the» должен следовать какой-то математический словарь, такой как «числитель» или «косинус».
Из самого маленького ИИ, обученного исследователями, с 512 признаками, только одна функция представляла «the», в то время как самый большой ИИ с 16 384 признаками был разделен на одну функцию, представляющую «the» в машинном обучении, одну функцию, представляющую «the» в комплексном анализе, и одну функцию, представляющую «the» в топологии и абстрактной алгебре.
Поэтому, если бы систему можно было модернизировать до ИИ с большим количеством смоделированных нейронов, характеристики, представляющие «Бога», скорее всего, разделились бы на две части: одна для значения «Бога» в религии, а другая для «Бога» во имя монстра.
Позже может быть Бог в христианстве, Бог в иудаизме, Бог в философии и так далее.
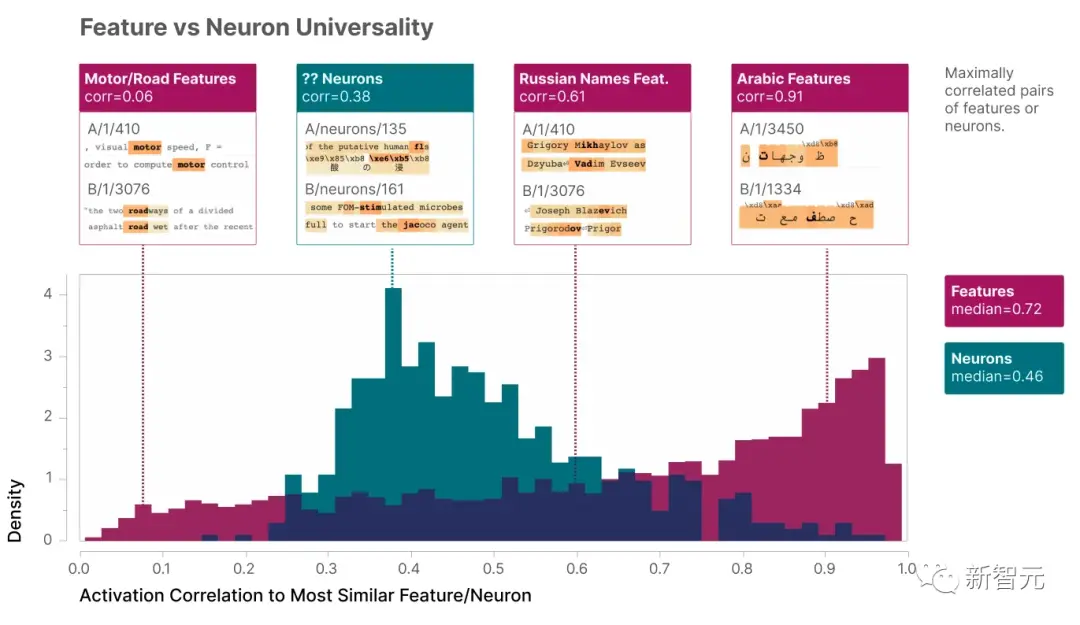
Исследовательская группа оценила субъективную интерпретируемость 412 групп реальных нейронов и соответствующих смоделированных нейронов и обнаружила, что интерпретируемость смоделированных нейронов в целом была хорошей:
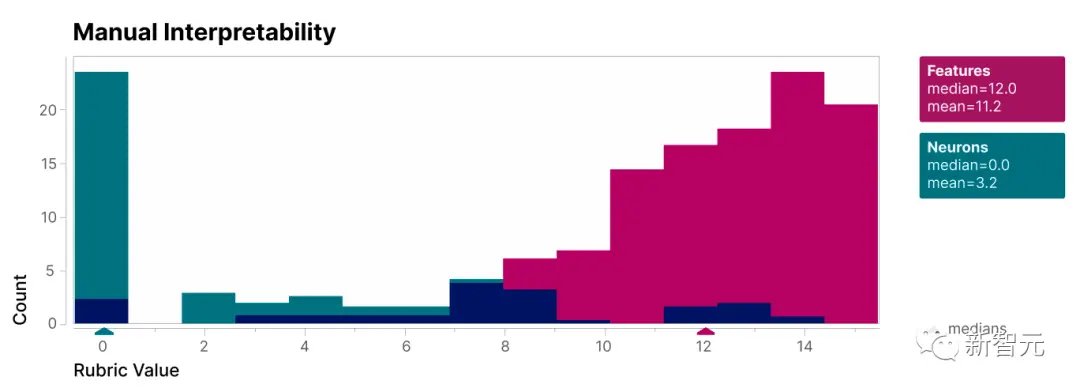 Некоторые признаки, такие как тот, который означает «Бог», используются для определенных понятий.
Некоторые признаки, такие как тот, который означает «Бог», используются для определенных понятий.
Многие другие хорошо интерпретируемые функции, в том числе некоторые из наиболее интерпретируемых, представляют собой «форматирование», используемое для представления текста, например, прописные или строчные буквы, английский или другие алфавиты и т. д.
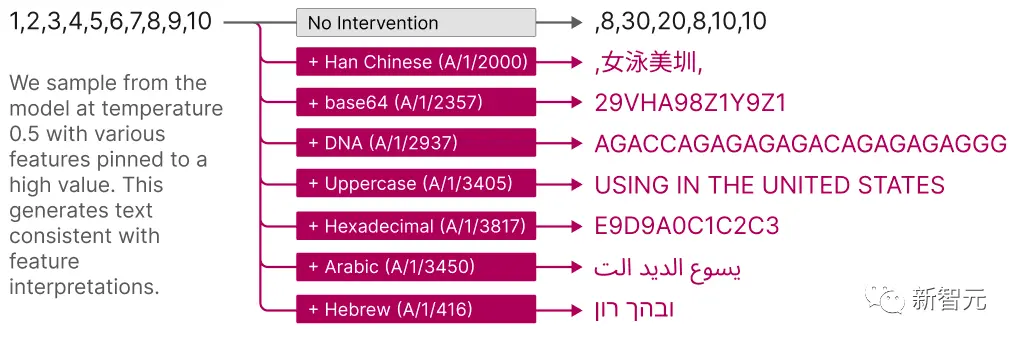 Насколько распространены эти функции? То есть, если вы обучите два разных ИИ с 4096 признаками на одних и тех же текстовых данных, будут ли они иметь большую часть одних и тех же признаков 4096? Будут ли все они обладать определенными характеристиками, представляющими «Бога»?
Насколько распространены эти функции? То есть, если вы обучите два разных ИИ с 4096 признаками на одних и тех же текстовых данных, будут ли они иметь большую часть одних и тех же признаков 4096? Будут ли все они обладать определенными характеристиками, представляющими «Бога»?
Или первый ИИ соединит «Бога» и «Годзиллу» вместе, а второй ИИ разделит их? Будет ли второй ИИ вообще не иметь функции «Бог», а вместо этого использовать это пространство для хранения некоторых других концепций, которые первый ИИ не смог бы понять?
Исследовательская группа проверила его и обнаружила, что их две модели ИИ очень похожи!
В среднем, если в первой модели есть один признак, то наиболее похожий признак во второй модели будет иметь медианную корреляцию 0,72.
Увидел душу ИИ
Что дальше?
В мае этого года OpenAI попыталась заставить GPT-4 (очень большую) понять GPT-2 (очень маленькую). Они попросили GPT-4 изучить 307 200 нейронов GPT-2 и сообщить о том, что он обнаружил.
GPT-4 обнаружил ряд интересных результатов и кучу случайной бессмыслицы, потому что они еще не овладели искусством проецирования реальных нейронов на смоделированные нейроны и анализа смоделированных нейронов.
Хотя результаты не были очевидными, это была действительно очень амбициозная попытка.
В отличие от этого ИИ в статье Anthropic, GPT-2 является реальным (хотя и очень маленьким) ИИ, который также произвел впечатление на широкую публику.
Но конечная цель исследований заключается в том, чтобы иметь возможность объяснить основные системы ИИ.
Команда объяснимости Anthropic признает, что они еще не сделали этого, в основном по нескольким причинам:
Во-первых, масштабирование автоэнкодеров — сложная задача. Для того, чтобы объяснить такую систему, как GPT-4 (или эквивалентную систему Клода от Anthropic), вам нужен ИИ-интерпретатор примерно такого же размера.
Но обучение ИИ в таком масштабе требует огромных вычислительных мощностей и финансовой поддержки.
Во-вторых, масштабируемость интерпретации также является проблемой.
Даже если мы найдем все смоделированные нейроны о Боге, Годзилле и всем остальном и нарисуем огромную диаграмму того, как они связаны.
Исследователям по-прежнему приходится отвечать на более сложные вопросы, а их решение требует сложных взаимодействий, включающих миллионы признаков и связей.
Поэтому должен быть какой-то автоматизированный процесс, какой-то более масштабный «пусть GPT-4 скажет нам, что делает GPT-2».
Наконец, что все это говорит о понимании человеческого мозга?
Люди также используют нейронные сети для рассуждений и обработки концепций.
В человеческом мозге очень много нейронов, и это то же самое, что и GPT-4.
Данные, доступные человеку, также очень скудны – есть много понятий (например, кальмар), которые редко встречаются в повседневной жизни.
Имитируем ли мы также более крупный мозг?
Это все еще очень новая область исследований, но есть некоторые предварительные результаты, свидетельствующие о том, что нейроны в зрительной коре человека кодируют черты каким-то гиперлокализованным образом, подобно паттернам, наблюдаемым в моделях искусственного интеллекта.
Ресурсы:
