大型モデル+検索:チェッカーと3人のプレイヤーのゲーム
巴比特_
出典: Brain polar body
 画像ソース: Unbounded AIによって生成
画像ソース: Unbounded AIによって生成
私たちは皆、アプリケーションに役立つようにするために大きなモデルが生まれなければならないことを知っています。 では、AIの大規模モデルの価値の可能性を最も早く最大限に発揮し、大規模モデルを着陸させる最初の目的地となるのはどのアプリケーションでしょうか? この質問になると、多くの人が最初に答えます。
一方では、これは、ChatGPTの爆発的な普及後、「大株主」であるMicrosoftが最初にその機能をBing検索に統合し、かつては大規模なモデルの利点に依存して業界の兄貴であるGoogleを選ぶと発表したためです。 そうなると、中国のAI界隈で大規模モデルが大規模に複製されるという文脈では、まずアプリケーション側で検索+大規模モデルを推進すると考えるのが自然です。
一方、検索エンジンには、AIと深く統合されているという利点が当然あります。 早くも2014年から2015年にかけて、BaiduやGoogleなどの伝統的な検索エンジンの巨人は、ディープラーニングやナレッジグラフなどのAIテクノロジーを検索に統合し始め、検索エンジンがユーザーの指示を理解し、検索結果の内部関連性を高める能力を向上させました。
大型模型+検索がちょうどいい時と場所といえることが分かります。 約1年間の調査の後、中国のAI産業の大規模モデル+検索アプリケーションは徐々に充実しています。 大規模モデルが探索にもたらす変化は完全には現れていませんが、比較的多様な探索のアイデアが形成されています。
大規模モデル+検索の現在の進捗状況を誰もがより鮮明に理解し、さまざまなアイデアの差別化を理解できるようにするため。 私たちは、大きなモデル+検索、チェッカーのゲームのような比喩を考えました。 すべてのプレイヤーの手にあるチェスの駒は同じです、つまり、ラージモデルテクノロジーと検索テクノロジーです。 そして、彼らの最終的な目標は同じです、つまり、大型モデルの時代に最初の人気のあるアプリケーションをインキュベートすることです。
しかし、チェスをプレイする過程で、それぞれが異なるチェスの動きを持っています。 現時点では、3つのジャンルに分かれています。
出場者1:検索エンジン用の拡張プラグインとしての大規模モデル
検索は、インターネット時代において、人と情報の最も頻繁な接触です。 検索エンジンは、ユーザーの意図と膨大な量の情報の両方を理解する必要があります。 情報と人々のハブとして、検索エンジンがインテリジェンスを向上させる必要性は尽きることがありません。
大規模モデルが検索エンジンにもたらす違いは、従来の検索エンジンのエクスペリエンスを向上させるだけでなく、AIGCモデルを通じてユーザーの意図と検索結果にさまざまなコンテンツ生成機能をもたらすことができることです。
たとえば、大規模なモデルでは、検索の精度が向上するだけでなく、複数の検索結果を 1 つのコンテンツ ボックスにマージして、ユーザーの時間を節約できます。 これは、従来の検索フレームワークの外部で追加の検索ツールをユーザーに提供することと同じです。
この考えに基づいて、業界は大規模モデル+検索の最初のモード、つまり検索エンジンの拡張プラグインとしての大規模モデルの機能を模索し始めました。 国内市場では、このジャンルの代表はBaiduです。
 検索事業は、Wenxinの大規模モデル機能による製品変革のためのBaiduの最初の停留所であると言えます。 この段階で、BaiduはAIGCの機能に基づく2つの「拡張プラグイン」を検索エンジンに追加しました。
検索事業は、Wenxinの大規模モデル機能による製品変革のためのBaiduの最初の停留所であると言えます。 この段階で、BaiduはAIGCの機能に基づく2つの「拡張プラグイン」を検索エンジンに追加しました。
1つ目は、最初の回答の情報を集約することです。
AIテクノロジーと検索を組み合わせるプロセスにおいて、Baiduは「最初の検索結果はユーザーのニーズを満たすことである」という概念を非常に重視しています。 大規模なモデル機能では、検索結果から重要な情報を集約して、コンテンツの概要を生成できます。 このモデルに基づいて、Baiduは検索エンジンの最初の回答に回答する機能を更新し、テキスト情報だけでなく、要約を要約する大規模なモデルを通じてビデオを理解します。 このモードでは、ユーザーがビデオ コンテンツで検索したい結果を追加することで、ユーザーはビデオを視聴できなくなりますが、最初の回答を通じてビデオ コンテンツの概要を直接取得できます。
Baiduが公開したデータによると、過去の最初の検索の満足度は約40%に過ぎませんでしたが、ラージモデル機能を追加すると、その満足度は70%に達しました。 検索エンジンのプラグインとしての大規模モデルの機能は、肯定的なフィードバックを得ることであることがわかります。
また、検索と組み合わせた「拡張プラグイン」型の大規模モデルとして、検索バーに加えてAIダイアログバーを提供するというものがあり、これは今年5月のMobile Ecological ConferenceでBaidu Searchが発表した「AIパートナー」機能である。
AIパートナーは、ユーザーとAIGCのQ&Aを行い、検索エンジンを使用する際に、回答のマーキング、情報源の提供、ドキュメントの要約などの機能の完了を支援し、他のツールやサービスの呼び出しもサポートできます。
言い換えれば、バイドゥは、検索エンジンのインターフェースと検索エンジンの外部で大規模なモデル機能に基づくAIGCプラグインを提供し、検索エンジンが複数の角度から大規模なモデル再構築を取得できるようにします。 偶然にも、この考え方は、GoogleがBardチャットボットを検索エンジンに統合したのと非常によく似ています
検索エンジンの伝統的な利点を持つメーカーは、拡張プラグインとして大規模なモデルを使用する傾向があり、「1+1は2より大きい」という考えを従来の検索エンジンに多角的に統合していることがわかります。
出場者2:ChatGPTライクな検索アプリ
従来の検索エンジンの機能を強化することに加えて、大規模なモデルは別の問題ももたらします:従来の検索フォームをバイパスして、AIGCの機能に基づいて新しい検索製品を直接生成することは可能ですか?
また、この可能性についても検討されています。 ChatGPT自体は、セマンティクスやマルチラウンドのQ&A、コンテンツ生成などを理解する能力を持っており、ある程度はこれも一種の「検索」と捉えることができます。 検索の内容がキーワードから質問やニーズに変わり、検索結果がWebページから直接生成されたテキストコンテンツに変わっただけです。
その結果、中国のAI業界で登場した新しいタイプの検索製品は、ChatGPTのような検索と呼ぶことができます。 その中でも代表的な「出場者」は、Kunlun Wanwei氏が立ち上げたTiangong AI検索です。
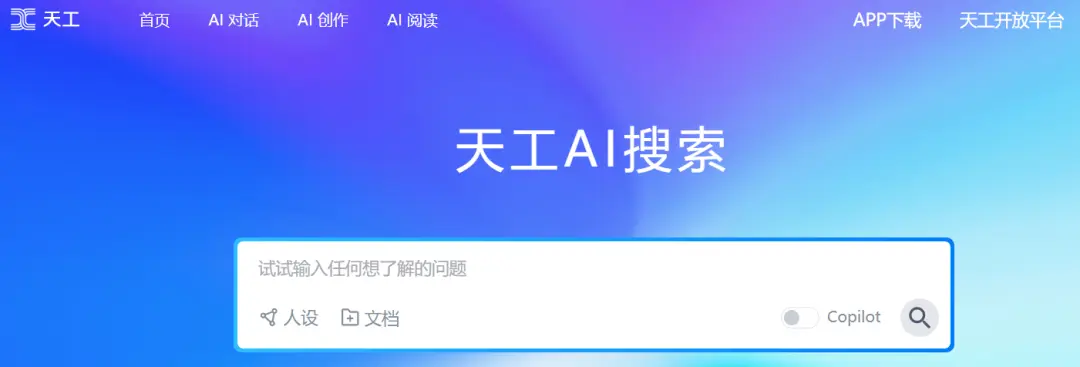 この種の検索エンジンは、AIGCを製品のコアロジックとして完全に採用しています。 ユーザーは自然言語を使用してニーズの意図を表現し、検索インターフェイスは、従来の検索エンジンのように多数のWebリンクを表示するのではなく、関連する回答に応答します。
この種の検索エンジンは、AIGCを製品のコアロジックとして完全に採用しています。 ユーザーは自然言語を使用してニーズの意図を表現し、検索インターフェイスは、従来の検索エンジンのように多数のWebリンクを表示するのではなく、関連する回答に応答します。
相対的に言えば、Tiangong AI検索の革新の1つはソースインデックスにあります。 ChatGPTなどのAIGCプラットフォームを使用する場合、AIが何に答えるかという不確実性に直面することがよくあります。 多くの質問の大きなモデルでは正しい答えを出すことができず、議論、文献ソース、ニュースソースなどを作り上げ、「AIの真面目なナンセンス」として広く不満が寄せられています。
Tiangong AI Searchは、回答の生成と参照情報ソースを同時に重視し、ユーザーが情報の参照を追跡できるようにし、AIGCプラットフォームの信頼性問題を大幅に回避します。 また、ニュースサイト、知識に関する質問と回答のプラットフォーム、ビデオなど、参照情報ソースも比較的豊富です。
しかし、現段階では、ChatGPTのような検索とAIGCプラットフォームの境界はまだ区別が難しく、ユーザーの認識は明確ではありません。 このモデルは、さらに普及し、ユーザーによってテストされる必要があります。
プレイヤー3:大型モデルランディング垂直検索
検索エンジンの状況が比較的安定した後、一般的な検索機会が大きくなくなった後、検索エンジンは垂直検索分野で努力し、この分野での継続的な検索需要でユーザーベースを統合することができます。 Sogou SearchとQuarkは、いずれも垂直検索の分野で力を入れています。 その中でもQuarkは、その垂直検索機能により、若いユーザーの間で好成績を収めています。
大規模モデル+検索の3つ目の考え方は、垂直検索で大規模モデルを先行してランディングすることです。 このようにして、特定の検索領域での自然言語理解能力と情報検索経験を強化します。 この分野では、現在の代表選手はQuarkです。 11月14日、アリババのインテリジェント情報ビジネスグループは、クォークラークの大型モデルを発表しました。 クォークラージモデルの適用は、独自の差別化されたポジショニングに基づいて、専門的な検索やその他の情報サービスの適用を優先します。 クォーク大規模モデルは、基本的な大規模言語モデルに加えて、医療や教育などの垂直モデルも導出する予定であり、クォークが専門知識の分野を重視していることがうかがえます。
 現在、医療、教育、人文社会科学が中心となって大規模模型を垂直探索しています。 これらの方向性は、情報源に対する要求が強く、キーワードが曖昧で、情報効率が低く、論理が強いという特徴があり、一般的な検索よりも大きなモデルが独自の特性を発揮するのに適している。 同時に、大規模モデルと垂直検索の組み合わせにより、製品コストを削減し、検索フィールドでの大規模モデルの全体的な効率を向上させることもできます。
現在、医療、教育、人文社会科学が中心となって大規模模型を垂直探索しています。 これらの方向性は、情報源に対する要求が強く、キーワードが曖昧で、情報効率が低く、論理が強いという特徴があり、一般的な検索よりも大きなモデルが独自の特性を発揮するのに適している。 同時に、大規模モデルと垂直検索の組み合わせにより、製品コストを削減し、検索フィールドでの大規模モデルの全体的な効率を向上させることもできます。
実際、垂直検索と大規模モデルの組み合わせのバリエーションもあり、つまり、各ネットワークディスクは現在、自然言語理解機能を備えた検索機能でオンラインになっています。 曖昧な説明や形容詞などの重要な情報を使用して、特に画像、ビデオ、その他のコンテンツのネットワーク ディスク データを取得できます。
これはすべてスーパーアプリの踏み台です
そこで問題となるのが、大規模モデル+探索の正解はどのモードかということです。
申し訳ありませんが、答えは待つことしかできません。
大規模モデル + 検索は、論理的に非常に有望な大規模モデル着陸シナリオです。 そのため、ChatGPTが爆発的に普及し始めた直後、MicrosoftはBingChatに大規模なモデル機能を組み込み、Google検索について多くの残酷な言葉を公開しました。 しかし、ほぼ1年後、Microsoftは検索ビジネスから多くのAI機能をスピンオフし、Googleの市場支配は影響を受けていません。 このシナリオでは、理論から実践にはまだ長い道のりがあることがわかります。
 国内市場を振り返ると、3つの探索モードはまだ別々に戦っていて、あまり対立がなく、ユーザー側では大規模モデル+検索の一般的な認識がなく、着地度すらChatGPT的な対話アプリ自体に遥かに劣っていることがわかります。 次の 3 つの理由が考えられます。
国内市場を振り返ると、3つの探索モードはまだ別々に戦っていて、あまり対立がなく、ユーザー側では大規模モデル+検索の一般的な認識がなく、着地度すらChatGPT的な対話アプリ自体に遥かに劣っていることがわかります。 次の 3 つの理由が考えられます。
**1.これら3回の大規模モデル+検索の試みでは、製品形態の0から1への突破は完了していません。 **以前の検索エンジンとAI対話製品を強化して完成させるために生まれたため、非常に興味深い製品の発火点はありません。
**2. この段階では、大規模モデルの検索エクスペリエンスの向上は、マス ユーザーのエクスペリエンスでは強くありません。 **学術、IT、その他の分野での専門的なツールとしてのみ使用できます。
**3.In なお、大型模型+検索の商品化余地は明確ではありません。 **大規模モデル技術が加わった後、検索製品のビジネスモデルや事業化レベルは大きく変化しておらず、資本市場からの注目度が低かった。
長い目で見れば、大規模モデル+検索の最終的な目標は、大規模モデルの時代におけるスーパーアプリケーションを形成することであるに違いない。 インターネット時代の検索エンジンの出現のように、人々の情報取得と相互作用のモードを完全に変えました。
そして、これが目標であるならば、今日の大規模モデル+検索探索は、必然的にチェスの駒の道の踏み台となるでしょう。 チェスの駒を跳ねさせ続けることによってのみ、将来、あるノードで質的な変化が起こるのです。
大きなモデルと検索を前進させ続けることができる限り、前景の光は暗闇よりもはるかに大きいままです。
免責事項:このページの情報は第三者から提供される場合があり、Gateの見解または意見を代表するものではありません。このページに表示される内容は参考情報のみであり、いかなる金融、投資、または法律上の助言を構成するものではありません。Gateは情報の正確性または完全性を保証せず、当該情報の利用に起因するいかなる損失についても責任を負いません。仮想資産への投資は高いリスクを伴い、大きな価格変動の影響を受けます。投資元本の全額を失う可能性があります。関連するリスクを十分に理解したうえで、ご自身の財務状況およびリスク許容度に基づき慎重に判断してください。詳細は免責事項をご参照ください。
コメント
0/400
コメントなし