“لا يزال الذكاء الاصطناعي أحد المسارات التي تستحق أكبر قدر من الاهتمام ولديها أكبر الفرص في Web3، وهذا المنطق لن يتغير بالتأكيد.”
** بقلم: إيان، Foresight Ventures**
ل؛د
بعد أشهر من الخوض في مجال الجمع بين الذكاء الاصطناعي والعملات المشفرة، أصبح فهم هذا الاتجاه أعمق. تجري هذه المقالة تحليلاً مقارنًا للمشاهدات المبكرة واتجاه المسار الحالي.*** يمكن للأصدقاء الذين هم على دراية بالمسار البدء في القراءة من القسم الثاني***.
- شبكة الطاقة الحاسوبية اللامركزية: في مواجهة تحديات الطلب في السوق، يتم التركيز بشكل خاص على الهدف النهائي المتمثل في اللامركزية وهو تقليل التكاليف. إن سمات المجتمع والرموز المميزة لـ Web3 تجلب قيمة لا يمكن تجاهلها، ولكنها تظل قيمة مضافة إلى مسار قوة الحوسبة في حد ذاتها، وليس تغييراً مزعجاً. وينصب التركيز على إيجاد طريقة لدمجها مع احتياجات المستخدم، بدلاً من تعمل شبكة الطاقة الحاسوبية اللامركزية بشكل أعمى كمكمل لنقص قوة الحوسبة المركزية.
- سوق الذكاء الاصطناعي: ناقش مفهوم سوق الذكاء الاصطناعي المالي ذو الارتباط الكامل والقيمة التي يقدمها المجتمع والرموز وأهميتها الحيوية. لا يركز مثل هذا السوق على قوة الحوسبة والبيانات الأساسية فحسب، بل يشمل أيضًا النموذج نفسه والتطبيقات ذات الصلة. تعد تمويل النماذج عنصرًا أساسيًا في سوق الذكاء الاصطناعي، فمن ناحية، فهي تجتذب المستخدمين للمشاركة بشكل مباشر في عملية إنشاء القيمة لنماذج الذكاء الاصطناعي، ومن ناحية أخرى، فإنها تخلق الطلب على قوة الحوسبة والبيانات الأساسية.
- يواجه Onchain AI وZKML تحديات مزدوجة تتعلق بالعرض والطلب، في حين توفر OPML حلاً أكثر توازناً من حيث التكلفة والكفاءة. على الرغم من أن OPML يعد ابتكارًا تكنولوجيًا، إلا أنه قد لا يحل التحدي الأساسي الذي يواجهه الذكاء الاصطناعي على السلسلة، وهو عدم وجود طلب.
- في طبقة التطبيق، تكون معظم مشاريع تطبيقات الذكاء الاصطناعي web3 ساذجة للغاية، والنقطة الأكثر منطقية لتطبيقات الذكاء الاصطناعي هي تعزيز تجربة المستخدم وتحسين كفاءة التطوير، أو العمل كجزء مهم من سوق الذكاء الاصطناعي.
1. مراجعة مسار الذكاء الاصطناعي
في الأشهر القليلة الماضية، قمت بإجراء بحث متعمق حول موضوع الذكاء الاصطناعي + التشفير، وبعد عدة أشهر من التراكم، أنا سعيد جدًا لأنني اكتسبت نظرة ثاقبة لاتجاه بعض المسارات في مرحلة مبكرة، ولكن يمكنني وانظر أيضًا أن هناك بعض الاتجاهات التي تلوح في الأفق الآن، وهذه ليست رؤية دقيقة.
**هذه المقالة تتحدث فقط عن الآراء ولا تعطي مقدمة **سوف تغطي عدة اتجاهات عامة للذكاء الاصطناعي في web3 وتظهر آرائي وتحليلاتي السابقة والحالية على المسار. قد يكون لوجهات النظر المختلفة إلهامات مختلفة، والتي يمكن النظر إليها بشكل نسبي وجدلي.

دعونا أولاً نراجع الاتجاهات الرئيسية لـ AI + crypto التي تم تحديدها في النصف الأول من العام:
1.1 قوة الحوسبة الموزعة
في “نظرة عقلانية إلى شبكة طاقة الحوسبة اللامركزية”، استنادًا إلى المنطق العام القائل بأن قوة الحوسبة ستصبح المورد الأكثر قيمة في المستقبل، يتم تحليل القيمة التي يمكن أن تقدمها العملات المشفرة لشبكة طاقة الحوسبة.
على الرغم من أن شبكات الطاقة الحاسوبية الموزعة اللامركزية لديها أكبر طلب على التدريب على نماذج الذكاء الاصطناعي الكبيرة، إلا أنها تواجه أيضًا أكبر التحديات والاختناقات التقنية. بما في ذلك مشكلات مزامنة البيانات المعقدة وتحسين الشبكة. بالإضافة إلى ذلك، تعد خصوصية البيانات وأمنها من القيود المهمة. على الرغم من وجود بعض التقنيات الحالية التي يمكن أن توفر حلولًا أولية، في مهام التدريب الموزعة واسعة النطاق، إلا أن هذه التقنيات لا تزال غير عملية، بسبب النفقات الحسابية والاتصالات الضخمة. من الواضح أن شبكات الطاقة الحاسوبية الموزعة اللامركزية لديها فرصة أفضل للتنفيذ في الاستدلال النموذجي، وهناك مساحة كافية للتنبؤ بالزيادات المستقبلية. ولكنها تواجه أيضًا تحديات مثل تأخير الاتصالات، وخصوصية البيانات، وأمن النماذج. بالمقارنة مع التدريب النموذجي، فإن التعقيد الحسابي وتفاعل البيانات أثناء الاستدلال أقل، وهو أكثر ملاءمة ليتم تنفيذه في بيئة موزعة.
1.2 سوق الذكاء الاصطناعي اللامركزي
في “أفضل محاولة لسوق الذكاء الاصطناعي اللامركزي”، ذُكر أن سوق الذكاء الاصطناعي اللامركزي الناجح يحتاج إلى الجمع بشكل وثيق بين مزايا الذكاء الاصطناعي وWeb3، واستخدام التوزيع وتأكيد الأصول وتوزيع الدخل واللامركزية. القيمة المضافة تعمل قوة الحوسبة المركزية على خفض عتبة تطبيقات الذكاء الاصطناعي، وتشجع المطورين على تحميل النماذج ومشاركتها، مع حماية حقوق خصوصية بيانات المستخدمين، وبناء منصة لتداول موارد الذكاء الاصطناعي ومشاركتها تكون صديقة للمطورين وتلبي احتياجات المستخدم.
وكانت الفكرة في ذلك الوقت (وقد لا تكون دقيقة تمامًا الآن) هي أن سوق الذكاء الاصطناعي القائم على البيانات يتمتع بإمكانات أكبر. يحتاج السوق الذي يعتمد بشكل كبير على النماذج إلى دعم عدد كبير من النماذج عالية الجودة، ولكن المنصات المبكرة تفتقر إلى قاعدة المستخدمين والموارد عالية الجودة، مما يجعل من الصعب على مقدمي النماذج الممتازة جذب نماذج عالية الجودة. البيانات لا مركزية وموزعة، ويمكن أن يؤدي جمعها وتصميم طبقة الحوافز وضمان ملكية البيانات إلى تجميع كمية كبيرة من البيانات والموارد القيمة، وخاصة بيانات المجال الخاص.
ويعتمد نجاح سوق الذكاء الاصطناعي اللامركزي على تراكم موارد المستخدم وتأثيرات الشبكة القوية. والقيمة التي يمكن للمستخدمين والمطورين الحصول عليها من السوق تتجاوز القيمة التي يمكنهم الحصول عليها خارج السوق. في المراحل الأولى من السوق، ينصب التركيز على تجميع نماذج عالية الجودة لجذب المستخدمين والاحتفاظ بهم، ثم بعد إنشاء مكتبة نماذج عالية الجودة وحواجز البيانات، يتم التحول إلى جذب المزيد من المستخدمين النهائيين والاحتفاظ بهم.
1.3 ZKML
تمت مناقشة قيمة الذكاء الاصطناعي على السلسلة في “AI + Web3 = ?” قبل مناقشة موضوع ZKML على نطاق واسع.
دون التضحية باللامركزية وانعدام الثقة، يتمتع الذكاء الاصطناعي onchain بفرصة قيادة عالم web3 إلى “المستوى التالي”. يشبه web3 الحالي المرحلة المبكرة من web2، وليس لديه القدرة بعد على تنفيذ تطبيقات أوسع أو إنشاء قيمة أكبر. تم تصميم Onchain AI بدقة لتوفير حل شفاف وغير جدير بالثقة.
1.4 تطبيق الذكاء الاصطناعي
في “AI + Crypto يبدأ الحديث عن ألعاب Web3 الموجهة للنساء - HIM”، جنبًا إلى جنب مع مشروع المحفظة “HIM”، يتم تحليل القيمة التي تجلبها النماذج الكبيرة في تطبيقات web3؛ أي نوع من الذكاء الاصطناعي + التشفير يمكنه جلب إلى المنتج للحصول على عوائد أعلى؟ بالإضافة إلى التطوير العميق لمادة LLM غير الموثوق بها على السلسلة من البنية التحتية إلى الخوارزميات، هناك اتجاه آخر يتمثل في التقليل من تأثير الصندوق الأسود على عملية الاستدلال في المنتج، وإيجاد سيناريوهات مناسبة لتنفيذ قدرات الاستدلال القوية للنماذج الكبيرة .

2. تحليل مسار الذكاء الاصطناعي الحالي
2.1 شبكة الحوسبة: هناك مجال كبير للخيال ولكن عتبة عالية
ويظل المنطق العام لشبكة الطاقة الحاسوبية دون تغيير، ولكنها لا تزال تواجه التحدي المتمثل في الطلب في السوق. فمن الذي قد يحتاج إلى حل أقل كفاءة واستقرارا؟ لذلك أعتقد أنه يجب علينا التفكير في النقاط التالية:
**ما فائدة اللامركزية؟ **
إذا سألت مؤسس شبكة الحوسبة اللامركزية الآن، فمن المحتمل أن يخبرك أن شبكة الحوسبة لدينا يمكنها تعزيز الأمان ومقاومة الهجمات، وتحسين الشفافية والثقة، وتحسين استخدام الموارد، وتحسين خصوصية البيانات والتحكم في المستخدم، والحماية من الرقابة والتدخل…
هذه أمور منطقية، وأي مشروع web3 يمكن أن يتضمن مقاومة الرقابة، وانعدام الثقة، والخصوصية، وما إلى ذلك، ولكن وجهة نظري هي أن هذه ليست مهمة. فكر في الأمر بعناية، ألا يمكن للخوادم المركزية أن تعمل بشكل أفضل من حيث الأمان؟ إن شبكات الطاقة الحاسوبية اللامركزية لا تحل بشكل أساسي مشكلة الخصوصية، ولا تزال هناك العديد من هذه التناقضات. لذلك: ** يجب أن يكون الهدف النهائي المتمثل في تحقيق اللامركزية في شبكة الطاقة الحاسوبية هو خفض التكاليف. كلما ارتفعت درجة اللامركزية، انخفضت تكلفة استخدام الطاقة الحاسوبية. **
لذلك، من الناحية الأساسية، “استخدام قوة الحوسبة الخاملة” هو أكثر من مجرد سرد طويل المدى. أعتقد أن ما إذا كان من الممكن بناء شبكة قوة حوسبة لا مركزية، يعتمد إلى حد كبير على ما إذا كان قد اكتشف النقاط التالية. :
** القيمة المقدمة من Web3 **
من الواضح أن مجموعة من تصميمات الرموز المميزة وآلية الحوافز/العقوبات المصاحبة لها تمثل قيمة مضافة قوية يقدمها المجتمع اللامركزي. بالمقارنة مع الإنترنت التقليدية، لا تعمل الرموز المميزة كوسيلة للمعاملات فحسب، بل تكمل بعضها البعض بعقود ذكية لتمكين البروتوكولات من تنفيذ آليات حوافز وحوكمة أكثر تعقيدًا. وفي الوقت نفسه، فإن انفتاح وشفافية المعاملات، وخفض التكاليف، وتحسين الكفاءة، كلها تستفيد من القيمة التي يجلبها التشفير. توفر هذه القيمة الفريدة مزيدًا من المرونة ومساحة للابتكار لتحفيز المساهمين.

ولكن في الوقت نفسه، آمل أيضًا أن يتم النظر إلى هذا “الملاءمة” الذي يبدو معقولاً بشكل عقلاني. بالنسبة لشبكات الحوسبة اللامركزية، فإن القيم التي تجلبها تقنية Web3 و blockchain هي مجرد “قيمة مضافة” من منظور آخر. وليس مجرد قيمة أساسية التخريب، لا يمكنه تغيير أساليب العمل الأساسية للشبكة بأكملها واختراق الاختناقات التقنية الحالية.
باختصار، تتمثل قيمة web3 في تعزيز جاذبية الشبكة اللامركزية، ولكنها لن تغير هيكلها الأساسي أو نموذج تشغيلها بالكامل، إذا كنت تريد أن تحتل الشبكة اللامركزية مكانًا حقيقيًا في موجة الذكاء الاصطناعي، الاعتماد فقط على قيمة web3 ليس كافيًا. لذلك، كما سيتم ذكره لاحقًا، فإن التكنولوجيا المناسبة تحل المشكلة الصحيحة، إن طريقة اللعب في شبكة طاقة الحوسبة اللامركزية لا تهدف بأي حال من الأحوال إلى حل مشكلة نقص طاقة حوسبة الذكاء الاصطناعي فحسب، بل لإعطاء فرصة لهذا المسار الذي ظل خامدًا لفترة طويلة. اللعب والأفكار.
قد يكون الأمر مثل تعدين أسرى الحرب أو تعدين التخزين، لتحقيق الدخل من قوة الحوسبة كأصل. في هذا النموذج، يمكن لمزودي الطاقة الحاسوبية الحصول على الرموز المميزة كمكافآت من خلال المساهمة بموارد الحوسبة الخاصة بهم. وتكمن الجاذبية في أنها توفر وسيلة لتحويل موارد الحوسبة مباشرة إلى مكاسب اقتصادية، وبالتالي تحفيز المزيد من المشاركين على الانضمام إلى الشبكة. وقد يعتمد أيضًا على الويب 3 لإنشاء سوق يستهلك قوة الحوسبة، ومن خلال تمويل المنبع من قوة الحوسبة (مثل النماذج)، يمكن أن يفتح نقاط الطلب التي يمكن أن تقبل قوة حوسبة غير مستقرة وبطيئة.
“هل تريد أن تفهم كيفية دمجها مع الاحتياجات الفعلية للمستخدمين؟ بعد كل شيء، فإن احتياجات المستخدمين والمشاركين ليست بالضرورة مجرد قوة حوسبة فعالة. يعد “كسب المال” دائمًا أحد أكثر الدوافع إقناعًا”.
** القدرة التنافسية الأساسية لشبكة طاقة الحوسبة اللامركزية هي السعر **
إذا كان علينا مناقشة قوة الحوسبة اللامركزية من القيمة الفعلية، فإن أكبر خيال يجلبه web3 هو تكلفة طاقة الحوسبة التي لديها الفرصة للضغط بشكل أكبر.
كلما ارتفعت درجة اللامركزية في عقد الطاقة الحاسوبية، انخفض سعر كل وحدة من قوة الحوسبة. ويمكن استنتاج ذلك من الاتجاهات التالية:
- مع إدخال الرمز المميز، يتم تغيير الدفع لموفر طاقة الحوسبة للعقدة من النقد إلى الرمز المميز الأصلي للبروتوكول، مما يقلل بشكل أساسي من تكاليف التشغيل؛
- يساهم الوصول بدون إذن والتأثير المجتمعي القوي لـ web3 بشكل مباشر في تحسين التكلفة التي يحركها السوق. يمكن لعدد أكبر من المستخدمين الفرديين والمؤسسات الصغيرة استخدام موارد الأجهزة الحالية للانضمام إلى الشبكة، وزيادة إمدادات الطاقة الحاسوبية، وقوة الحوسبة في يزداد السوق، وينخفض سعر العرض من الطاقة. في أوضاع الإدارة الذاتية والمجتمعية.
- سيعمل سوق الطاقة الحاسوبية المفتوحة الذي أنشأه البروتوكول على تعزيز المنافسة السعرية بين مزودي الطاقة الحاسوبية، وبالتالي خفض التكاليف بشكل أكبر.
الحالة: تشينمل

بكل بساطة: ChainML عبارة عن منصة لا مركزية توفر قوة حاسوبية للاستدلال والضبط الدقيق. على المدى القصير، ستقوم تشينمل بتنفيذ Council استنادًا إلى إطار عمل وكيل الذكاء الاصطناعي مفتوح المصدر، ومن خلال محاولة Council (روبوت الدردشة الذي يمكن دمجه في تطبيقات مختلفة)، ستؤدي إلى زيادة الطلب على شبكات الحوسبة اللامركزية. على المدى الطويل، ستكون chainml عبارة عن منصة AI + web3 كاملة (والتي سيتم تحليلها بالتفصيل لاحقًا)، بما في ذلك سوق النماذج وسوق الطاقة الحاسوبية.
"أعتقد أن تخطيط المسار الفني لـ ChainML معقول جدًا. كما أنهم يفكرون بوضوح في المشكلات المذكورة من قبل. إن الغرض من قوة الحوسبة اللامركزية ليس بالتأكيد على قدم المساواة مع قوة الحوسبة المركزية وتوفير إمدادات طاقة حاسوبية كافية لصناعة الذكاء الاصطناعي ويتمثل الهدف في خفض التكاليف تدريجيا للسماح لأطراف الطلب المناسبة بقبول هذا المصدر الأقل جودة للطاقة الحاسوبية. بعد ذلك، في المراحل الأولى من المشروع، عندما لا يتمكن البروتوكول من الحصول على عدد كبير من عقد طاقة الحوسبة اللامركزية، ينصب التركيز على إيجاد مصدر مستقر وفعال لقوة الحوسبة. لذلك، من منظور مسار المنتج، ينبغي البدء بنهج مركزي. وتشغيل روابط المنتج في المراحل المبكرة، والبدء في تجميع العملاء من خلال إمكانات bd القوية، وتوسيع السوق، ثم توزيع موفري طاقة الحوسبة المركزية تدريجيًا على الشركات الصغيرة ذات التكاليف المنخفضة، وأخيرًا نقل عقد الطاقة الحاسوبية المنتشرة على مساحة واسعة. هذه هي فكرة chainml فرق تسد.
من منظور تخطيط جانب الطلب، قامت ChainML ببناء MVP لبروتوكول البنية التحتية المركزي، ومفهوم التصميم محمول. ونحن نقوم بتشغيل هذا النظام مع العملاء منذ فبراير من هذا العام، وبدأنا استخدامه في بيئة الإنتاج في أبريل من هذا العام. يعمل حاليًا على Google Cloud، ولكن استنادًا إلى Kubernetes وتقنيات أخرى مفتوحة المصدر، يمكن نقله بسهولة إلى بيئات أخرى (AWS، وAzure، وCoreweave، وما إلى ذلك). في المستقبل، سيتم تطبيق اللامركزية على هذا البروتوكول تدريجيًا، وتوزيعه على السحابات المتخصصة، وأخيرًا على القائمين بالتعدين الذين يوفرون القدرة الحاسوبية.
2.2 سوق الذكاء الاصطناعي: هناك مجال أكبر للخيال
يُطلق على هذا القطاع اسم AI Markerplace، وهو ما يحد من الخيال إلى حد ما. بالمعنى الدقيق للكلمة، يجب أن يكون “سوق الذكاء الاصطناعي” الخيالي حقًا بمثابة منصة وسيطة تمول سلسلة النماذج بأكملها، وتغطي كل شيء بدءًا من قوة الحوسبة الأساسية والبيانات إلى النموذج نفسه والتطبيقات ذات الصلة. كما ذكرنا من قبل، كان التناقض الرئيسي في الأيام الأولى لقوة الحوسبة اللامركزية هو كيفية خلق الطلب، والسوق ذات الحلقة المغلقة التي تمول سلسلة الذكاء الاصطناعي بأكملها لديها الفرصة لخلق مثل هذا الطلب.
يذهب شيء من هذا القبيل:
يعتمد سوق الذكاء الاصطناعي الذي يدعمه web3 على قوة الحوسبة والبيانات، مما يجذب المطورين لبناء النماذج أو ضبطها من خلال بيانات أكثر قيمة، ثم تطوير التطبيقات القائمة على النماذج المقابلة. ويتم تطوير هذه التطبيقات والنماذج واستخدامها في نفس الوقت. يخلق الطلب على قوة الحوسبة. بفضل التحفيز من خلال الرموز والمجتمعات، فإن مهام جمع البيانات في الوقت الفعلي القائمة على المكافآت أو الحوافز الطبيعية للمساهمة في البيانات لديها الفرصة لتوسيع وتوسيع المزايا الفريدة لطبقة البيانات في هذا السوق. وفي الوقت نفسه، تؤدي شعبية التطبيقات أيضًا إلى إرجاع بيانات أكثر قيمة إلى طبقة البيانات.
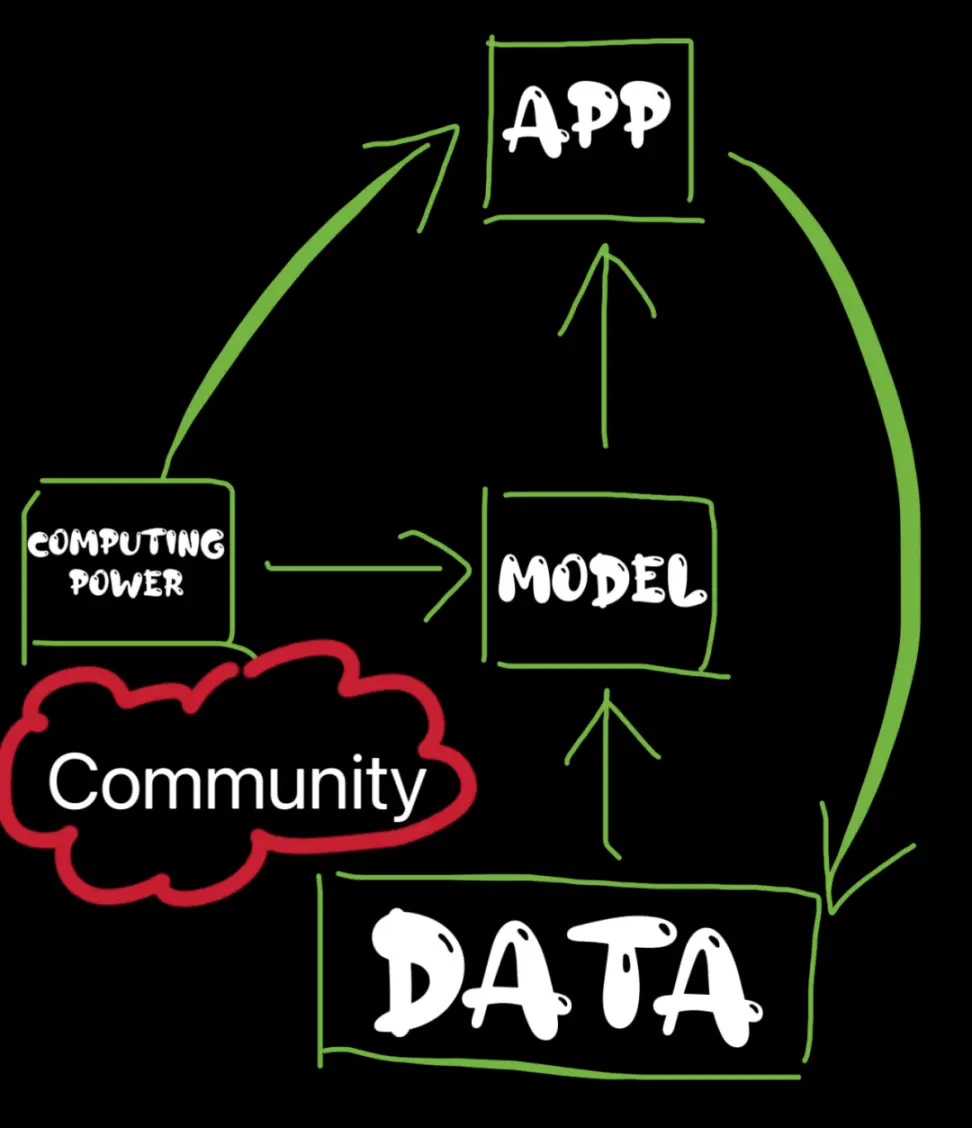
مجتمع
بالإضافة إلى القيمة التي تجلبها الرموز المميزة المذكورة سابقًا، يعد المجتمع بلا شك أحد أكبر المكاسب التي جلبتها web3 وهو القوة الدافعة الأساسية لتطوير النظام الأساسي. إن دعم المجتمع والرموز يمنح جودة المساهمين والمحتوى المساهم فرصة لتجاوز جودة المؤسسات المركزية. على سبيل المثال، يعد تحقيق تنوع البيانات ميزة لهذا النوع من المنصات، وهو أمر بالغ الأهمية لبناء ذكاء اصطناعي دقيق وغير متحيز. وفي الوقت نفسه، فهو أيضًا عنق الزجاجة لاتجاه البيانات الحالي.
أعتقد أن جوهر النظام الأساسي بأكمله يكمن في النموذج. لقد أدركنا في وقت مبكر جدًا أن نجاح سوق الذكاء الاصطناعي يعتمد على ما إذا كانت هناك نماذج عالية الجودة، وما هي الحوافز التي لدى المطورين لتقديم النماذج على منصة لا مركزية؟ ولكن يبدو أننا نسينا أيضًا التفكير في مشكلة ما. فالبنية التحتية ليست قوية مثل المنصات التقليدية، ومجتمع المطورين ليس ناضجًا مثل المنصات التقليدية، ولا تتمتع السمعة بميزة المتحرك الأول التي تتمتع بها المنصات التقليدية. منصات الذكاء الاصطناعي التقليدية، لديها قاعدة مستخدمين ضخمة وبنية تحتية ناضجة ومشاريع web3 لا يمكن تجاوزها إلا في الزوايا.
قد تكمن الإجابة في أمولة نماذج الذكاء الاصطناعي**
- يمكن اعتبار النماذج بمثابة سلعة. وقد يكون التعامل مع نماذج الذكاء الاصطناعي باعتبارها أصولا قابلة للاستثمار ابتكارا مثيرا للاهتمام في أسواق ويب 3 والأسواق اللامركزية. يتيح هذا النوع من الأسواق للمستخدمين المشاركة بشكل مباشر في عملية خلق القيمة لنماذج الذكاء الاصطناعي والاستفادة منها. تشجع هذه الآلية أيضًا السعي وراء نماذج عالية الجودة ومساهمات المجتمع، لأن فوائد المستخدم ترتبط ارتباطًا مباشرًا بأداء النموذج وتأثيراته التطبيقية؛
- يمكن للمستخدمين الاستثمار من خلال تعهد النماذج: إن إدخال آلية تقاسم الإيرادات من ناحية يشجع المستخدمين على اختيار النماذج المحتملة ودعمها، ويوفر حوافز اقتصادية لمطوري النماذج لإنشاء نماذج أفضل. من ناحية أخرى، بالنسبة لأصحاب المصلحة، فإن المعيار الأكثر بديهية للحكم على النماذج (خاصة نماذج توليد الصور) هو إجراء قياسات فعلية متعددة، وهذا يوفر طلبًا على قوة الحوسبة اللامركزية للمنصة، والتي قد تكون أيضًا أحد الحلول المذكورة سابقًا هو “من الذي يرغب في استخدام طاقة حاسوبية أقل كفاءة وأكثر استقرارًا؟”
**2.3 Onchain AI: تجاوز OPML في المنعطفات؟ **
ZKML: كلا من الطلب والعرض في ورطة
الأمر المؤكد هو أن الذكاء الاصطناعي على السلسلة يجب أن يكون اتجاهًا مليئًا بالخيال ويستحق دراسة متعمقة. يمكن للاختراقات في مجال الذكاء الاصطناعي على السلسلة أن تضيف قيمة غير مسبوقة إلى web3. ولكن في الوقت نفسه، فإن العتبة الأكاديمية العالية للغاية لـ ZKML ومتطلبات البنية التحتية الأساسية ليست في الواقع مناسبة لمعظم الشركات الناشئة. لا تحتاج معظم المشاريع بالضرورة إلى دعم LLM غير موثوق به لتحقيق اختراقات في قيمتها الخاصة.
ولكن لا يلزم نقل جميع نماذج الذكاء الاصطناعي إلى السلسلة لاستخدام ZK لجعلها غير موثوقة. فمثلما هو الحال مع معظم الناس، لا يهتمون بكيفية قيام روبوت الدردشة باستخلاص الاستعلام وإعطاء النتائج، ولا يهتمون بما إذا كان النشر المستقر المستخدم هو إصدار معين من الذكاء الاصطناعي. بنية النموذج أو إعدادات المعلمة المحددة. في معظم السيناريوهات، يركز معظم المستخدمين على ما إذا كان النموذج يمكن أن يعطي نتائج مرضية، بدلاً من التركيز على ما إذا كانت عملية الاستدلال غير موثوقة أو شفافة.
إذا كان الإثبات لا يؤدي إلى تكاليف عامة مائة ضعف أو تكاليف تفكير أعلى، فربما لا تزال ZKML لديها القدرة على القتال، ولكن في مواجهة تكاليف الاستدلال المرتفعة على السلسلة والتكاليف المرتفعة، فإن أي جانب من جوانب الطلب لديه سبب للتشكيك في الحاجة إلى Onchain AI. الجنس.
النظر من جانب الطلب
ما يهتم به المستخدمون هو ما إذا كانت النتائج التي يقدمها النموذج منطقية. وما دامت النتائج معقولة، فمن الممكن أن نقول إن الثقة التي جلبها ZKML لا قيمة لها؛ ولنتخيل أحد السيناريوهات التالية:
- إذا كان روبوت التداول القائم على الشبكة العصبية يجلب للمستخدمين ربحًا مئة ضعف في كل دورة، فمن سيتساءل عما إذا كانت الخوارزمية مركزية أو يمكن التحقق منها؟
*بالمثل، إذا بدأ روبوت التداول هذا في خسارة أموال للمستخدمين، فيجب على فريق المشروع التفكير أكثر في كيفية تحسين قدرات النموذج بدلاً من إنفاق الطاقة ورأس المال على جعل النموذج قابلاً للتحقق. هذا هو التناقض في متطلبات ZKML، وبعبارة أخرى، فإن إمكانية التحقق من النموذج لا تحل بشكل أساسي شكوك الناس حول الذكاء الاصطناعي في العديد من السيناريوهات، وهو أمر متناقض بعض الشيء.
النظر من جانب العرض
لا يزال الطريق طويلا لتطوير الأدلة القادرة على دعم نماذج التنبؤ الضخمة. وانطلاقا من المحاولات الحالية للمشاريع الرائدة، يكاد يكون من المستحيل رؤية اليوم الذي يتم فيه وضع النماذج الضخمة على السلسلة.
بالرجوع إلى مقالتنا السابقة حول ZKML، فإن هدف ZKML تقنيًا هو تحويل الشبكات العصبية إلى دوائر ZK، وتكمن الصعوبة في:
- دائرة ZK لا تدعم أرقام الفاصلة العائمة؛
- يصعب تحويل الشبكات العصبية واسعة النطاق.
انطلاقا من التقدم الحالي:
- تدعم أحدث مكتبة ZKML بعض شبكات ZKization البسيطة للشبكات العصبية، ويقال إنها قادرة على ربط نماذج الانحدار الخطي الأساسية. ولكن هناك عدد قليل جدًا من العروض التوضيحية الموجودة.
- من الناحية النظرية، يمكن أن يدعم الحد الأقصى ~**100 مليون معلمة، ولكن هذا نظري فقط. **
إن التقدم في تطوير ZKML لم يلب التوقعات. وانطلاقًا من التقدم المحرز في مختبر معامل المشاريع الرائدة الحالي وإثبات EZKL، يمكن تحويل بعض النماذج البسيطة إلى دوائر ZK لتسلسل النماذج أو إثبات الاستدلال. على السلسلة. ولكن هذا بعيد كل البعد عن الوصول إلى قيمة ZKML، ويبدو أنه لا يوجد دافع أساسي لاختراق عنق الزجاجة الفني. فالمسار الذي يفتقر بشدة إلى الطلب غير قادر بشكل أساسي على جذب انتباه المجتمع الأكاديمي، مما يعني أن المزيد من ذلك هو من الصعب إنشاء نقطة تعريف جيدة لجذب/تلبية الطلب المتبقي وقد يكون هذا أيضًا هو دوامة الموت التي تقتل ZKML.
**OPML: مرحلة انتقالية أم نهاية اللعبة؟ **
الفرق بين OPML وZKML هو أن ZKML يثبت عملية الاستدلال الكاملة، بينما يعيد OPML تنفيذ جزء من عملية الاستدلال عند الاعتراض على الاستدلال. من الواضح أن أكبر مشكلة تحلها OPML هي أن التكلفة/النفقات العامة مرتفعة للغاية. وهذا تحسين عملي للغاية.
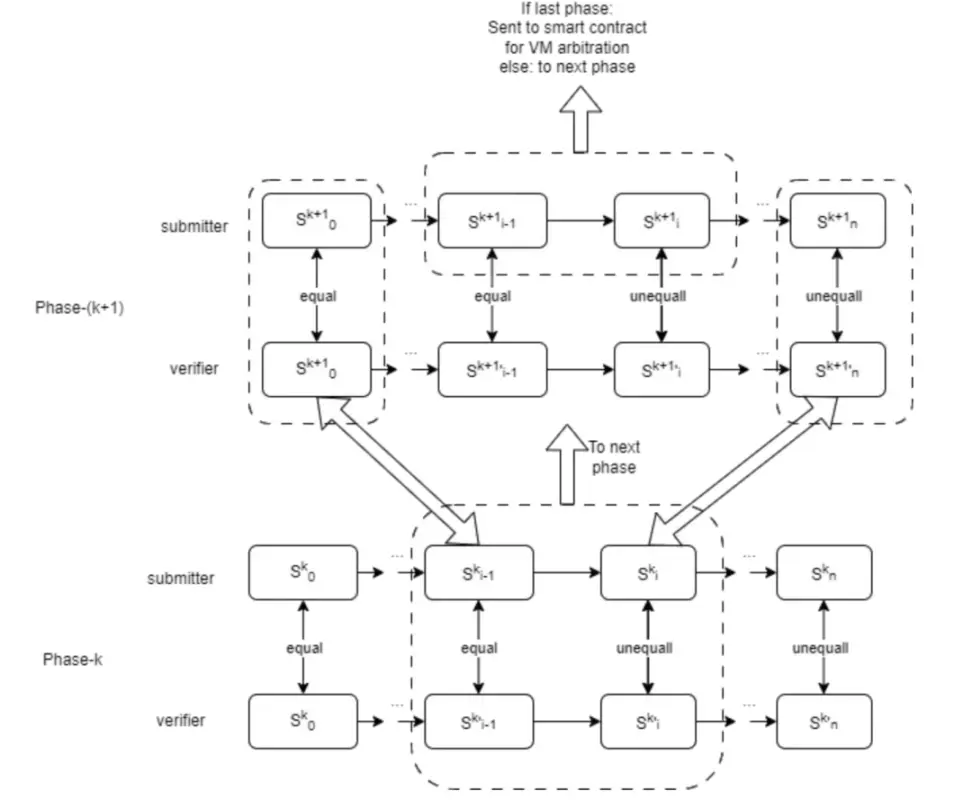
بصفته مؤسس OPML، قدم فريق HyperOracle البنية والعملية المتقدمة من مرحلة واحدة إلى opML متعددة المراحل في “opML هو كل ما تحتاجه: تشغيل نموذج 13B ML في Ethereum”:
- قم ببناء جهاز افتراضي للتنفيذ خارج السلسلة والتحقق عبر السلسلة لضمان التكافؤ بين VM غير المتصل بالإنترنت و VM المطبق في العقد الذكي على السلسلة.
- من أجل ضمان كفاءة الاستدلال لنموذج الذكاء الاصطناعي في الجهاز الافتراضي، تم تنفيذ مكتبة DNN خفيفة الوزن ومصممة خصيصًا (والتي لا تعتمد على أطر التعلم الآلي الشائعة مثل Tensorflow أو PyTorch). وفي الوقت نفسه، قام الفريق أيضًا يوفر مكتبة يمكنها الجمع بين نماذج Tensorflow وPyTorch. وقد تم تحويل البرنامج النصي إلى هذه المكتبة خفيفة الوزن.
- قم بتجميع رمز استنتاج نموذج الذكاء الاصطناعي في تعليمات برنامج VM من خلال التجميع المتقاطع.
- تتم إدارة صورة VM من خلال شجرة Merkle. سيتم فقط تحميل جذر Merkle الذي يمثل حالة VM إلى العقد الذكي الموجود على السلسلة.
ولكن من الواضح أن هذا التصميم به عيب رئيسي، وهو أنه يجب إجراء جميع الحسابات داخل الجهاز الظاهري، مما يعيق استخدام تسريع GPU/TPU والمعالجة المتوازية، مما يحد من الكفاءة. لذلك تم تقديم opML متعدد المراحل.
- فقط في المرحلة النهائية، يتم إجراء الحساب في الجهاز الافتراضي.
- في مراحل أخرى، يتم حساب انتقالات الحالة في البيئة الأصلية، وبالتالي الاستفادة من قدرات وحدة المعالجة المركزية (CPU)، ووحدة معالجة الرسومات (GPU)، وTPU، ودعم المعالجة المتوازية. يقلل هذا الأسلوب من الاعتماد على الأجهزة الافتراضية، ويحسن أداء التنفيذ بشكل كبير، ويصل إلى مستوى مماثل للبيئة الأصلية.
المرجع: __Ui5I9gFOy7-da_jI1lgEqtnzSIKcwuBIrk-6YM0Y

لنكن واقعيين
يعتقد بعض الناس أن OPML عبارة عن مرحلة انتقالية قبل تحقيق ZKML الشامل، ولكن من الأكثر واقعية أن نفكر في الأمر باعتباره مقايضة للذكاء الاصطناعي Onchain على أساس هيكل التكلفة وتوقعات التنفيذ. ولعل اليوم الذي يتم فيه تحقيق ZKML بالكامل لن يأتي أبدا، "على الأقل لدي موقف متشائم تجاه هذا. ثم سيتعين على الضجيج الخاص بـ Onchain AI في النهاية مواجهة التنفيذ والتكلفة الأكثر واقعية. ثم قد تكون OPML هي أفضل ممارسة لـ Onchain AI. تمامًا مثلما لم تكن بيئة OP و ZK بديلاً على الإطلاق علاقة. .
على الرغم من ذلك، لا تنس أن أوجه القصور في المتطلبات السابقة لا تزال موجودة. إن تحسين OPML على أساس التكلفة والكفاءة لا يحل بشكل أساسي "نظرًا لأن المستخدمين يهتمون أكثر بعقلانية النتائج، فلماذا يجب نقل الذكاء الاصطناعي إلى السلسلة لتحقيق ذلك “غير جدير بالثقة؟” مشاكل متعارضة تمامًا مع بعضها البعض، الشفافية، والملكية، وانعدام الثقة. إن هذه الهواة تكون في الواقع مبهرجة للغاية عند دمجها، ولكن هل يهتم المستخدمون حقًا؟ وفي المقابل، يجب أن تنعكس القيمة في قدرة النموذج على التفكير.
أعتقد أن تحسين التكلفة هذا هو محاولة مبتكرة وقوية من الناحية الفنية، ولكن من حيث القيمة فهو أشبه بدوار سيئ؛
ربما يكون مسار Onchain للذكاء الاصطناعي في حد ذاته مجرد بحث عن مسامير بمطرقة، ولكن هذا صحيح. يتطلب تطوير صناعة مبكرة استكشافًا مستمرًا لمجموعات مبتكرة من التقنيات عبر المجالات، وإيجاد أفضل ملاءمة من خلال التشغيل المستمر. هذا خطأ. لم يكن أبدًا تصادمًا واختبارًا للتكنولوجيا، بل كان متابعة عمياء للاتجاهات التي تفتقر إلى التفكير المستقل.
2.4 طبقة التطبيق: 99% من وحوش الغرز
"يجب أن أقول إن محاولات الذكاء الاصطناعي في طبقة تطبيق web3 تأتي بالفعل واحدة تلو الأخرى. يبدو أن الجميع يخافون من الخوف، لكن 99% من عمليات التكامل يجب أن تظل في عمليات التكامل فقط. ليست هناك حاجة للاعتماد على قدرة gpt المنطقية على رسم الخرائط قيمة المشروع نفسه.
من منظور طبقة التطبيق، هناك طريقتان تقريبًا للخروج:
- استخدام قوة الذكاء الاصطناعي لتحسين تجربة المستخدم وتحسين كفاءة التطوير: في هذه الحالة، لن يكون الذكاء الاصطناعي هو العنصر الأساسي، بل في أغلب الأحيان عامل من وراء الكواليس يساهم بصمت، بل وحتى غير مبال بالمستخدمين؛ على سبيل المثال، web3 فريق Game HIM ذكي جدًا فيما يتعلق بالجمع بين محتوى اللعبة والذكاء الاصطناعي والتشفير. لقد استوعبوا النقاط المتوافقة للغاية ويمكن أن تولد أكبر قيمة. من ناحية، يستخدمون الذكاء الاصطناعي كأداة أداة قيمة الإنتاج لتحسين كفاءة التطوير وجودته. ومن ناحية أخرى، تحسين تجربة الألعاب للمستخدم من خلال قدرات الذكاء الاصطناعي المنطقية. يجلب الذكاء الاصطناعي والتشفير قيمة مهمة للغاية، لكنهما في الأساس لا يزالان يستخدمان وسائل تكنولوجيا الأدوات. الميزة الحقيقية وجوهرها من المشروع لا تزال قدرة الفريق على تطوير الألعاب.
- ادمج مع سوق الذكاء الاصطناعي لتصبح جزءًا مهمًا موجهًا نحو المستخدم من النظام البيئي بأكمله.
3. أخيراً…
إذا كان هناك أي شيء يحتاج حقًا إلى التأكيد عليه أو تلخيصه: فلا يزال الذكاء الاصطناعي أحد المسارات التي تستحق أكبر قدر من الاهتمام ولديها أكبر الفرص في web3، وهذا المنطق العام بالتأكيد لن يتغير؛
لكنني أعتقد أن ما يستحق الاهتمام الأكبر هو أسلوب اللعب في سوق الذكاء الاصطناعي. بشكل أساسي، يتماشى تصميم هذه المنصة أو البنية التحتية مع احتياجات خلق القيمة ويرضي مصالح جميع الأطراف. من منظور كلي، يخلق منتجات تتجاوز النموذج أو قوة الحوسبة نفسها. إنها جذابة بما يكفي للحصول على طريقة فريدة لالتقاط القيمة في الويب 3. وفي الوقت نفسه، تتيح أيضًا للمستخدمين المشاركة بشكل مباشر في موجة الذكاء الاصطناعي بطريقة فريدة.
ربما خلال ثلاثة أشهر سأقلب أفكاري الحالية، لذا:
ما ورد أعلاه هو مجرد وجهة نظري الحقيقية حول هذا المسار، وهي في الواقع لا تشكل أي نصيحة استثمارية!
المرجع
opML هو كل ما تحتاجه: قم بتشغيل نموذج 13B ML في Ethereum: __Ui5I9gFOy7-da_jI1lgEqtnzSIKcwuBIrk-6YM0Y
