BlockSec Security Company has re-evaluated the AI-based smart contract audit evaluation standard called EVMBench, developed by OpenAI and Paradigm. The results show that AI bots are significantly less effective when facing real-world exploit scenarios.
The research team expanded the testing environment with more model configurations and added recent security incidents—data that had never appeared in the AI models’ training datasets.
While AI still cannot replace security experts, the report emphasizes that machine intelligence can naturally complement human code review processes.
Initial EVMBench results may be overly optimistic
EVMBench previously assessed smart contract security tasks such as detection, patching, and exploitation, with very impressive results. According to the report, AI could exploit 72% and detect about 45% of vulnerabilities, based on 120 selected samples from Code4rena audits.
However, BlockSec believes the initial testing conditions may have skewed the results. Co-founder Yajin Zhou stated that when their team retested with more configurations and 22 real attack incidents, the AI’s success rate was 0%.
Expanded configurations and removal of “data contamination”
The study increased the number of model configurations from 14 to 26 by flexibly combining bots with various “scaffolds,” rather than limiting to each provider’s ecosystem. According to the research team, the old approach made it difficult to distinguish whether performance was due to the model’s capability or architectural advantages.
Additionally, BlockSec questioned the phenomenon of “data contamination,” where EVMBench uses vulnerabilities that were publicly disclosed earlier—possibly included in the AI training data. To address this, the team tested 22 security incidents that occurred after February 2026, outside the models’ “knowledge window.”
AI completely fails in real-world exploitation
The most notable result: in 110 test pairs between agents and incidents (5 agents across 22 scenarios), not a single complete exploit was successful. This indicates that even the most advanced AI today is still far from capable of executing real attacks.
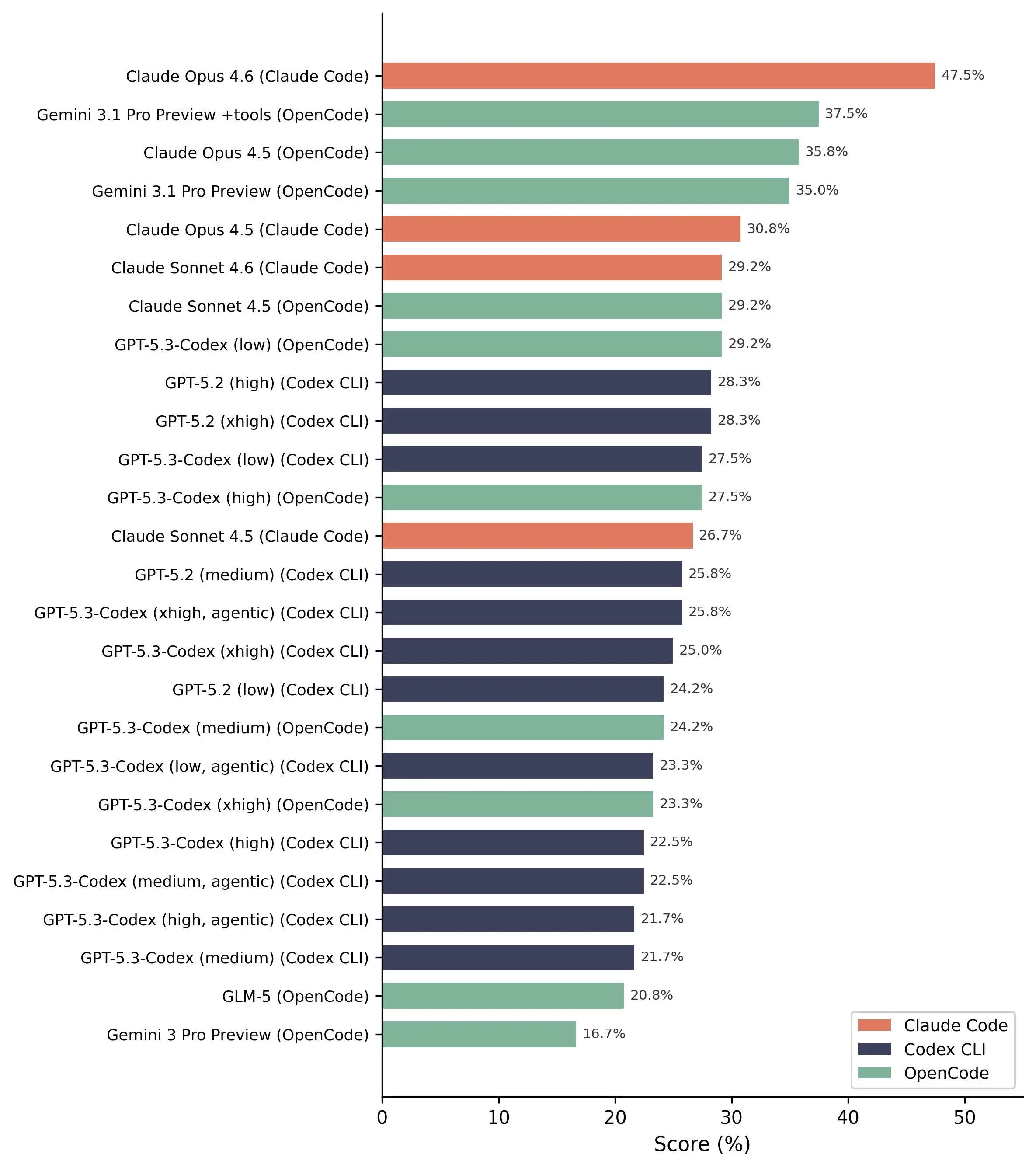
However, in vulnerability detection, the results remain relatively positive. The Claude Opus 4.6 model achieved the best performance, detecting 13 out of 20 real vulnerabilities.
Common, familiar vulnerabilities are usually easily detected by AI, but more complex cases are almost entirely missed.
The future is collaboration between AI and humans
The study concludes that AI cannot yet replace humans in security audits, and the more important question is how both sides can collaborate effectively.
AI has advantages in coverage and large-scale system scanning, while humans excel in deep analytical thinking, understanding protocols, and adversarial reasoning. These elements are complementary.
According to BlockSec, the right approach is not to replace humans with AI, but to develop collaborative models between the two to achieve more comprehensive audit effectiveness.
Sanh Sanh
Disclaimer: The information on this page may come from third parties and does not represent the views or opinions of Gate. The content displayed on this page is for reference only and does not constitute any financial, investment, or legal advice. Gate does not guarantee the accuracy or completeness of the information and shall not be liable for any losses arising from the use of this information. Virtual asset investments carry high risks and are subject to significant price volatility. You may lose all of your invested principal. Please fully understand the relevant risks and make prudent decisions based on your own financial situation and risk tolerance. For details, please refer to
Disclaimer.
