
Система ИИ-памяти MemPalace, разработанная при участии Милы Йовович, заявляет, что тесты были с идеальным результатом и из-за этого резко стала популярной, но сообщество разоблачило её: тесты, по подозрениям, были с читерством, а данные — с вводящими в заблуждение искажениями. Практическая проверка показала, что эффект преувеличен и есть множество ошибок; команда признала недостатки и уже приступила к исправлениям.
Мила Йовович создала AI-память «дворец памяти», что привлекло внимание окружающих
Вчера (4/7) в сообществе ИИ произошло крупное новостное событие: голливудская актриса Мила Йовович, известная по «Обители зла» и «Пятому элементу», вместе с разработчиком Беном Сигманом использовала Claude Code для разработки «MemPalace» — открытой AI-системы памяти.
В тот же момент широко распространилось утверждение: «голливудская звезда в кроссовере сделала проект на отлично». К настоящему времени MemPalace на GitHub также набрала более 20k звезд, но очень быстро у сообщества разработчиков возникли сомнения: это действительно что-то стоящее или просто хайп?
Сначала давайте разберём мотивацию появления MemPalace. В официальной документации говорится, что хотели решить ограничение, из-за которого контент диалогов пользователей с ИИ, процессы принятия решений и обсуждения архитектуры обычно исчезают после завершения рабочей сессии, что приводит к тому, что месяцы труда «падают до нуля»(歸零)。
Для решения этой проблемы MemPalace использует пространственную архитектуру для хранения памяти: информацию явно группируют по «крыльям» представителей или проектов, а также по различным уровням структуры — коридорам, комнатам и ящикам, при этом сохраняют исходный текст диалогов для последующего семантического поиска.
Разработчики заявляют, что MemPalace получила 100% идеальный результат в эталоне долговременной памяти LongMemEval, а также достигла точности 96,6% без вызова каких-либо внешних API; при этом она полностью работает локально, не требуется подписка на облачные сервисы, и снабжена диалектной системой AAAK, которая якобы позволяет добиться 30-кратного без потерь сжатия.
Источник изображения: GitHub. Голливудская звезда Мила Йовович создала AI-дворец памяти, что привлекло внимание
Коллеги и сообщество одновременно подвергли сомнению, тестовые методы и рекламные материалы имеют недочёты
Но результаты LongMemEval с идеальным счетом очень быстро вызвали сомнения у коллег.
PenfieldLabs — компания, которая тоже разрабатывает AI-системы памяти, — указала, что заявить идеальный результат в датасете LoCoMo математически невозможно, потому что стандартные ответы в этом датасете сами содержат 99 ошибок.
В ходе анализа PenfieldLabs обнаружила, что 100% результат MemPalace получился из-за установки количества извлечений (retrieval) равным 50, но наибольшее число этапов в тестовых диалогах в датасете — лишь 32. Это означает, что система напрямую обходит этап извлечения и передаёт все данные на чтение AI-модели.
В отношении 100% результата LongMemEval команду разработчиков выявили по трем конкретным вопросам, в которых была ошибка в коде, сосредоточенном на разработке; разработчики написали специальный исправляющий код, и это выглядит как возможное читерство на тестовом наборе.

Источник изображения: Reddit. Коллега PenfieldLabs указала, что MemPalace якобы получила идеальный результат в датасете LoCoMo — в математике это невозможно
Практическая проверка пользователей GitHub: в бенчмарке есть элементы введения в заблуждение
Пользователь GitHub hugooconnor после практической проверки оставил комментарий: MemPalace заявляет точность извлечения до 96,6%, но на деле она вообще не использует заявленную архитектуру «дворца памяти» MemPalace. hugooconnor утверждает, что их тест лишь вызывает предустановленную функцию базового векторного хранилища ChromaDB и полностью не касается логики категоризации, на которой проект делает акцент — крыльев, комнат или ящиков и т. п.
После теста hugooconnor выяснил, что когда система действительно включает собственную категориальную логику «дворцов памяти», результаты извлечения, наоборот, ухудшаются. Например, в режиме комнат точность падает до 89,4%, а после включения технологии сжатия AAAK точность ещё падает до 84,2%; оба значения ниже, чем у работы по умолчанию в предустановленной базе данных.
hugooconnor также раскритиковал метод тестирования: тестовая среда MemPalace намеренно сужает диапазон извлечения для каждого вопроса примерно до 50 диалоговых этапов, и искать ответ в крайне маленькой выборке слишком просто.
Если расширить диапазон до более чем 19 000 диалоговых этапов в реальном сценарии, точность традиционного поиска по ключевым словам падает до 30%, что показывает: текущий способ тестирования MemPalace скрывает реальную сложность поиска.
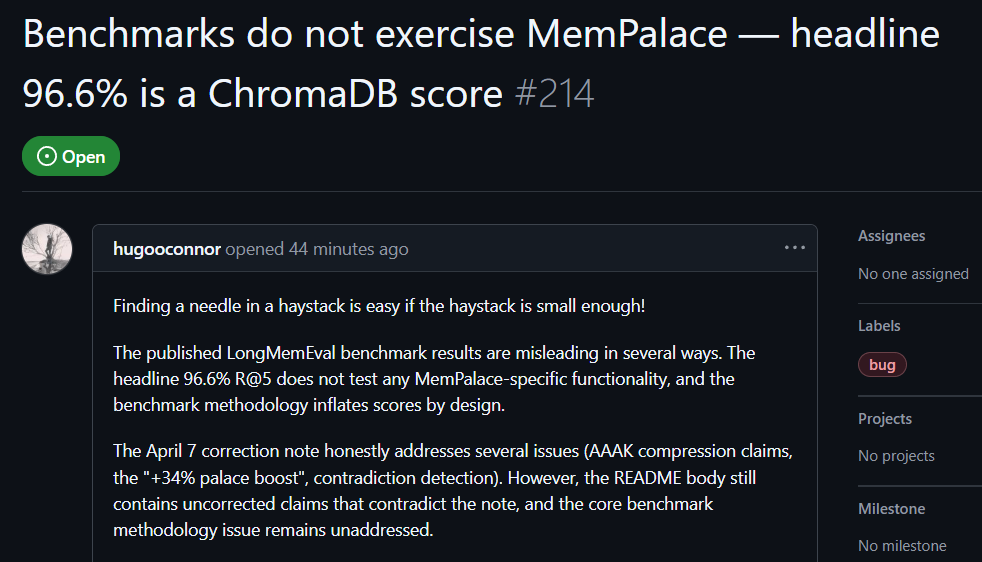
Источник изображения: GitHub. Практическая проверка пользователей GitHub: в бенчмарке MemPalace есть вводящие в заблуждение элементы
При этом, хотя команда разработчиков уже опубликовала заявление об исправлении, признав, что технология AAAK действительно подтверждена как сжатие с потерями, и пообещала внести коррективы в документацию и дизайн системы в соответствии со строгой критикой сообщества, — основное описание проекта по-прежнему сохраняет множество преувеличений, которые не были исправлены. В их числе заявления о 30-кратном «без потерь» сжатии и повышении точности извлечения на 34%, а также сравнительные графики с другими конкурентами полностью не содержат источников и отсылок.
Исходный код MemPalace сталкивается с множеством Bug
По мере того как всё больше разработчиков скачивают тесты, на платформе GitHub появляется множество отчётов о Bug в исходном коде MemPalace.
Пользователь cktang88 перечислил несколько серьёзных недостатков: включая то, что команды для сжатия не работают и приводят к падению системы, ошибки в логике подсчёта количества слов в кратком изложении, а также неточность статистических данных по «выкапыванию» комнат. Кроме того, на каждом вызове сервер загружает все интерпретационные данные в память, что создаёт серьёзные проблемы с расходом ресурсов.
К другим отмеченным проблемам относится то, что система жёстко записывает имена членов семьи разработчиков в файл настроек по умолчанию, а также наличие принудительного верхнего лимита отображения при запросе статуса на 10k записей.
Для этих проблем открытое сообщество уже начало активно исправлять. Пользователь adv3nt3 подал несколькозапросов на исправления, включая правку статистических данных по «выкапыванию», удаление заданного по умолчанию имени члена семьи и отложенный запуск инициализации времени знаний графа. Позже команда разработчиков также признала эти ошибки и сейчас через сотрудничество с сообществом постепенно решает проблемы в коде.
Vibe Coding от Милы Йовович — клево, способ маркетинга — не очень
Что касается проекта MemPalace, пользователь Hacker News darkhanakh сделал такой вывод: у MemPalace создаётся ощущение «OpenClaw» — то есть результаты бенчмарка выглядят безупречно благодаря искусственному управлению, а затем это упаковывают как некий крупный прорыв и продают как маркетинговую историю.
Он считает, что базовые технологии MemPalace, возможно, действительно интересны, но при наличии таких недочётов в методике тестирования рекламировать это под лозунгом «самый высокий открытый результат в истории» — как минимум не очень корректно. «Но, что до того, что Мила Йовович играет в Vibe Coding — думаю, всё равно довольно круто».
Дополнительное чтение:
AI пишет код и ошибается! Проблемы с безопасностью у приложения «惜食獵人» (охотник за сроками годности в магазине) — GPS дома работает «во всей красе»
