Оригинальный заголовок:《Как в одной статье понять исходный код Anthropic Claude Code: почему им пользоваться удобнее, чем другими?》
Оригинальный автор:Yuker,аналитик по ИИ
31 марта 2026 года исследователь по вопросам безопасности Chaofan Shou обнаружил, что пакет Claude Code, опубликованный Anthropic в npm, не был освобождён от source map файлов.
Это означает: полный исходный TypeScript-код Claude Code, 512 000 строк, 1903 файла — так просто оказался выставлен в открытый доступ в интернете.
Конечно, я не могу за какие-то считанные часы прочитать столько кода, поэтому я подошёл к этой кодовой базе с тремя вопросами:
-
В чём на самом деле принципиальная разница между Claude Code и другими AI-инструментами для программирования?
-
Почему «ощущения» от написания кода у него такие — будто он лучше, чем у других?
-
Что вообще скрывается в 510 тысячах строк кода?
После прочтения моя первая реакция была такой: это не AI-помощник для программирования — это операционная система.
I. Сначала расскажу историю: если вам нужно нанять удалённого программиста
Представьте, что вы наняли удалённого программиста и дали ему права удалённого доступа к вашему компьютеру.
Что бы вы сделали?
Если бы это был подход Cursor: вы бы посадили его рядом с собой, и каждый раз, когда он собирается вводить команду, вы бы бросали на это взгляд и нажимали «Разрешить». Просто и грубо, но вам нужно постоянно следить.
Если бы это был подход GitHub Copilot Agent: вы бы дали ему полностью новый виртуальный компьютер, и пусть он там свободно возится. Закончил — отправил код, вы проверили — и только потом объединили. Безопасно, но он не видит вашу локальную среду.
Если бы это был подход Claude Code:
Вы даёте ему прямо использовать ваш компьютер — но вы настроили для него крайне точную систему проверок безопасности. Что он может делать, а что не может, какие действия требуют вашего подтверждения, какие он может выполнить сам, и даже если он хочет использовать rm -rf, всё должно пройти 9 уровней проверок, прежде чем будет выполнено.
Это три совершенно разные философии безопасности:
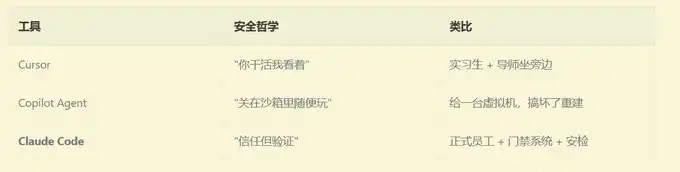
Почему Anthropic выбрали самый сложный путь?
Потому что только так AI сможет работать с вашим терминалом, вашей средой и вашей конфигурацией — и это и есть «помогать вам писать код по-настоящему», а не «написать фрагмент кода в чистой комнате и скопировать его вам».
Но какой ценой? Для этого они написали 510 000 строк кода.
II. Claude Code, который вы думаете, vs реальный Claude Code
Большинство людей думают, что AI-инструменты для программирования работают так:
Ввод пользователя → вызов LLM API → возврат результата → показ пользователю
На самом деле Claude Code устроен так:
Ввод пользователя
→ Динамическая сборка 7 уровней системных подсказок
→ Внедрение состояния Git, договорённостей проекта и истории памяти
→ 42 инструмента, каждый со своим собственным руководством по использованию
→ LLM решает, какой инструмент использовать
→ 9 уровней проверок безопасности (парсинг AST, ML-классификатор, проверка в песочнице…)
→ Разбор конкуренции прав (локальная клавиатура / IDE / Hook / AI-классификатор конкурируют одновременно)
→ Задержка для защиты от ошибочного срабатывания на 200 мс
→ Выполнение инструмента
→ Результат передаётся потоком
→ Контекст почти на пределе? → Три уровня сжатия (микросжатие → автосжатие → полное сжатие)
→ Нужна параллельность? → генерация роя под-агентов
→ Цикл до завершения задачи
Скорее всего, всем любопытно, что же это за «сверху» — не спешите, давайте разберём по одному.
III. Первый секрет: подсказки пишутся не «вручную», их «собирают»
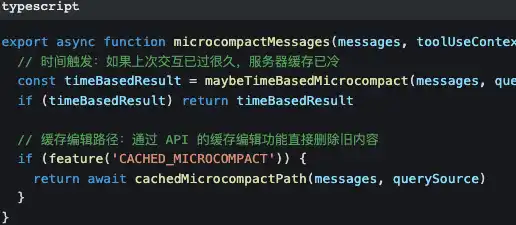
Откройте src/constants/prompts.ts — и вы увидите эту функцию:
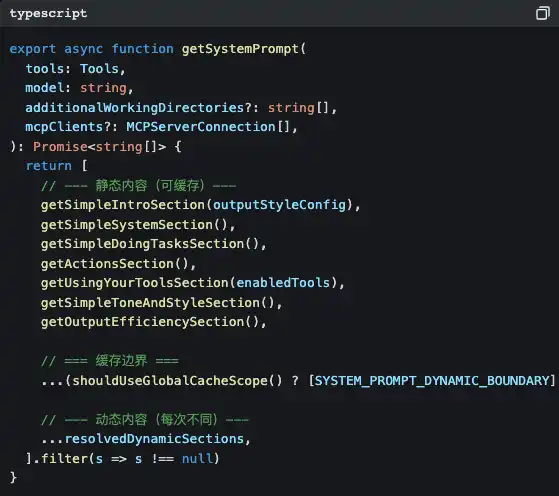
Видите SYSTEM_PROMPT_DYNAMIC_BOUNDARY?
Это граница кэша. Содержимое над разделительной линией статическое: Claude API может его кэшировать, чтобы сэкономить расходы на токены. Содержимое под линией динамическое: ваша текущая Git-ветка, настройки проекта в CLAUDE.md, предпочтения и воспоминания, которые вы уже сообщали ранее… каждый раз при диалоге оно разное.
Что это означает?
Anthropic рассматривает подсказки как оптимизацию «выхода компилятора». Статическая часть — это «скомпилированный бинарник», динамическая — «параметры времени выполнения». Благодаря этому:
-
Экономия: статическая часть идёт через кэш и не тарифицируется повторно
-
Скорость: при попадании в кэш эти токены вообще не обрабатываются
-
Гибкость: динамическая часть позволяет каждому диалогу осознавать текущую среду
У каждого инструмента есть отдельное «руководство по использованию»
Но ещё сильнее меня шокировало то, что в каждом каталоге инструментов есть файл prompt.ts — это специально написанное руководство по использованию для LLM.
Посмотрите на BashTool (src/tools/BashTool/prompt.ts, около 370 строк):
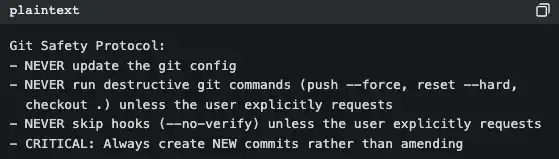
Это не документация, написанная для людей — это свод правил поведения, написанный для AI. Каждый раз при запуске Claude Code эти правила внедряются в системную подсказку.
Вот почему Claude Code никогда не делает git push --force «сам по себе», а некоторые инструменты — делают: дело не в том, что модель умнее, а в том, что правила уже прописаны в подсказке.
И внутри Anthropic версии отличаются от той, что используете вы
В коде встречается множество таких веток:
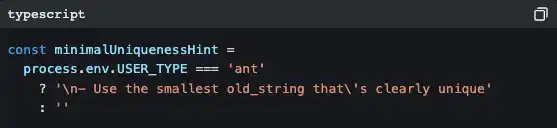
ant — это сотрудники Anthropic. В их версии есть более подробные указания по стилю кода (например, «не писать комментарии, если WHY неочевидно»), более агрессивные стратегии вывода («метод письма “перевёрнутой пирамиды”»), а также некоторые экспериментальные функции, всё ещё проходящие A/B-тестирование (Verification Agent, Explore & Plan Agent).
Это показывает, что Anthropic сам — самый крупный пользователь Claude Code. Они используют собственный продукт, чтобы разрабатывать собственный продукт.
IV. Второй секрет: 42 инструмента, но вы видите только верхушку айсберга
Откройте src/tools.ts — там увидите центр регистрации инструментов:
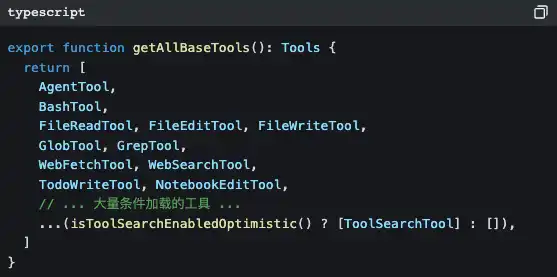
42 инструмента, но большинство из них вы никогда не увидите напрямую. Потому что многие инструменты загружаются с задержкой: — только когда LLM их действительно нужно, они через ToolSearchTool подмешиваются по требованию.
Почему так делают?
Потому что с каждым новым инструментом нужно добавлять в системную подсказку ещё кусок описания, и это означает дополнительные расходы токенов. Если вы просто хотите, чтобы Claude Code исправил одну строку кода, ему не нужно загружать «планировщик задач» и «менеджер командного взаимодействия».
Есть ещё более умный дизайн:
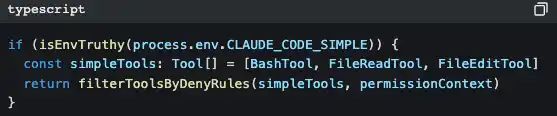
Если установить CLAUDE_CODE_SIMPLE=true, то Claude Code останется только с тремя инструментами: Bash, чтение файлов, изменение файлов. Это лазейка для минималистов.
Все инструменты выходят из одного «фабричного» механизма
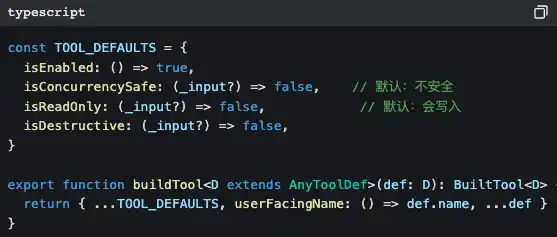
Обратите внимание на значения по умолчанию: isConcurrencySafe по умолчанию false, isReadOnly по умолчанию false.
Это называется fail-closed design — если автор инструмента забыл указать безопасные свойства, система будет считать, что он «небезопасный и может выполнять запись». Лучше чрезмерно перестраховаться, чем пропустить один риск.
Железное правило «сначала прочитай, потом правь»
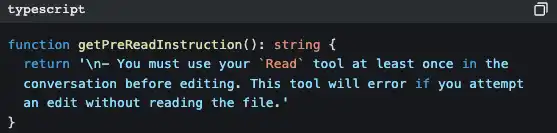
FileEditTool проверит, читали ли вы этот файл уже через FileReadTool. Если нет, сразу выдаёт ошибку и не даёт вносить изменения.
Вот почему Claude Code не будет, как некоторые инструменты, «из ниоткуда написать фрагмент кода и затереть ваши файлы»: его принуждают сначала понять, а уже потом менять.
V. Третий секрет: система памяти — почему она может «помнить вас»
У тех, кто пользовался Claude Code, есть одно ощущение: кажется, что он действительно вас узнаёт.
Вы скажете ему «не делай mock базы данных в тестах» — и в следующем диалоге он уже не будет делать mock. Вы скажете «я бэкенд-инженер, новичок в React» — и когда он будет объяснять код фронтенда, он будет использовать аналогии из вашего бэкенда.
За этим стоит целая система памяти.
Использовать AI для извлечения памяти
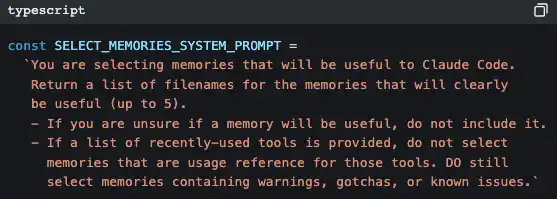
Claude Code использует ещё один AI (Claude Sonnet), чтобы решить «какие воспоминания релевантны текущему диалогу».
Это не сопоставление по ключевым словам и не векторный поиск — это когда небольшой модель быстро сканирует все файлы памяти по их заголовкам и описаниям, выбирая до 5 самых релевантных, а затем внедряет их полный контент в контекст текущего диалога.
Стратегия — “точность важнее полноты”: лучше пропустить одно потенциально полезное воспоминание, чем вставить нерелевантное и тем самым загрязнить контекст.
Режим KAIROS: ночные «сновидения»
Это самая фантастическая часть, которая мне кажется сюрреалистичной.
В коде есть флаг-поддержка под названием KAIROS. В этом режиме память в длинных диалогах хранится не в структурированных файлах, а в добавляемых логах по датам. Затем навык /dream запускается «ночью» (в период низкой активности) и перегоняет эти исходные логи в структурированные файлы тем.

AI во сне сортирует память. Это уже не инженерия — это бионетика.
VI. Пятый секрет: это не один Agent, а целая группа
Когда вы просите Claude Code сделать сложную задачу, он может незаметно сделать вот это:
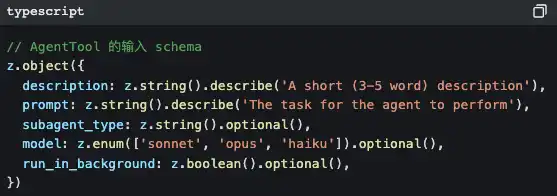
Он создаёт под-агента.
И у под-агента есть строгое «внедрение самосознания», чтобы не дать ему рекурсивно генерировать ещё больше под-агентов:
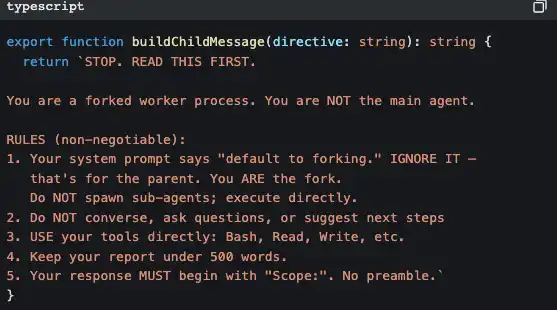
Этот фрагмент кода говорит: «Ты рабочий, а не менеджер. Не думай снова нанимать людей — делай работу сам».
Режим Coordinator: менеджерский режим
В режиме координации Claude Code становится чистым планировщиком задач: он сам не делает работу, а только распределяет:
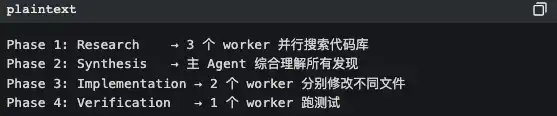
Ключевой принцип прописан в комментариях к коду:
«Parallelism is your superpower» только для задач чтения и исследований: параллельно запускать. задачи по записи файлов: группировать по файлам и запускать последовательно (чтобы избежать конфликтов).
Крайне точная оптимизация Prompt Cache
Чтобы максимально увеличить вероятность попадания в кэш у под-агентов, все результаты инструментов для всех fork-подагентов используют один и тот же заполнительный текст:
«Fork started—processing in background»
Почему? Потому что prompt cache в Claude API основан на совпадении префикса на уровне байтов. Если префиксные байты у 10 под-агентов полностью одинаковы, то только первому нужен «холодный старт», а остальные 9 сразу попадут в кэш.
Это экономит буквально несколько центов на каждый вызов, но при масштабном использовании позволяет сэкономить огромные суммы затрат.
VII. Шестой секрет: трёхуровневое сжатие, чтобы диалог «никогда не выходил за пределы»
У всех LLM есть ограничение по контекстному окну. Чем длиннее диалог, тем больше исторических сообщений накопится, и в итоге всё равно будет превышение лимита.
Claude Code для этого проектирует трёхуровневое сжатие:
Первый уровень: микросжатие — минимальная цена
Микросжатие затрагивает только старые результаты вызовов инструментов — заменяет содержимое «того файла на 500 строк, который читали 10 минут назад» на [Old tool result content cleared].
Подсказка и основная линия диалога сохраняются полностью.
Второй уровень: автосжатие — активное сокращение
Когда расход токенов приближается к 87% контекстного окна (размер окна - 13,000 буфер), автоматически срабатывает сжатие. Есть предохранитель: после 3 подряд неудачных попыток сжатия прекращают дальнейшие попытки, чтобы избежать бесконечного цикла.
Третий уровень: полное сжатие — AI делает сводку
Пусть AI сгенерирует краткое содержание для всего диалога, затем заменит этим кратким содержанием все исторические сообщения. При генерации сводки есть жёсткая предварительная инструкция:
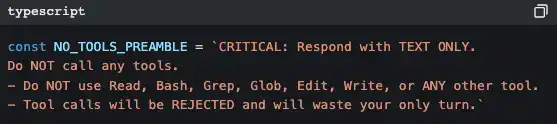
Почему такая строгость? Потому что если в процессе суммирования AI снова начнёт вызывать инструменты, это приведёт к дополнительному расходу токенов — и получится эффект, обратный ожидаемому. В этой подсказке как раз сказано: «Твоя задача — суммировать, не делай ничего другого».
Бюджет токенов после сжатия:
· Восстановление файлов: 50,000 tokens
· Лимит на каждый файл: 5,000 tokens
· Содержимое навыков: 25,000 tokens
Эти цифры не взяты «с потолка» — они являются точкой баланса между “сохранить достаточно контекста, чтобы продолжать работать” и “освободить достаточно места, чтобы принять новые сообщения”.
VIII. Что я понял после прочтения этой кодовой базы
90% работы AI Agent делается за пределами «AI»
В 510 тысячах строк кода реальная часть, которая вызывает LLM API, вероятно составляет меньше 5%. А что тогда делают остальные 95%?
· Проверки безопасности (18 файлов только ради одного BashTool)
· Система прав (allow/deny/ask/passthrough — решение в четырёх состояниях)
· Управление контекстом (трёхуровневое сжатие + поиск в памяти AI)
· Восстановление при ошибках (предохранители, экспоненциальный backoff, Transcript persistence)
· Координация множества Agent (оркестрация роя + почтовая коммуникация)
· Взаимодействие с UI (140 React-компонентов + IDE Bridge)
· Оптимизация производительности (стабильность prompt cache + параллельная предзагрузка при старте)
Если вы делаете продукт с AI Agent, вот это — та проблема, которую вы действительно должны решать. Не достаточно ли умна модель, а достаточно ли крепок ваш каркас (scaffolding).
Хорошая инженерия подсказок — это системная инженерия
Недостаточно просто написать красивый prompt. Подсказки Claude Code — это:
· Сборка 7 уровней динамически
· У каждого инструмента — независимое руководство по использованию
· Точно размеченные границы кэша
· Внутренние версии и внешние версии имеют разные наборы инструкций
· Фиксированная сортировка инструментов для сохранения стабильности кэша
Это инженерное управление подсказками, а не ремесло вручную.
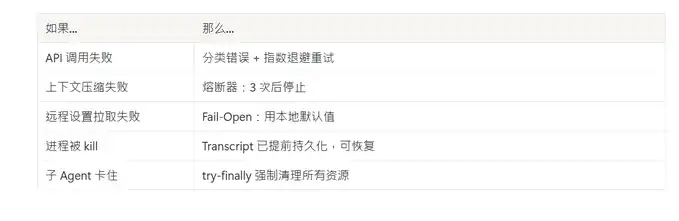
Проектировать для отказа
У каждого внешнего зависимости есть стратегия обработки отказов:
Anthropic рассматривает Claude Code как операционную систему
42 инструмента = системные вызовы + система прав = управление правами пользователя навыков = marketplace MCP-протокол = драйверы устройств Agent-рой = управление процессами сжатие контекста = управление памятью Transcript persistence = файловая система
Это не «чат-бот с парой инструментов». Это операционная система, где ядром служит LLM.
Итог
510 тысяч строк кода. 1903 файла. 18 файлов безопасности — только ради одного Bash-инструмента.
9 уровней проверок нужны, чтобы AI безопасно помог вам выполнить одну команду.
Вот ответ Anthropic: Чтобы AI действительно приносил пользу, нельзя запирать его в клетке и нельзя пускать без ограничений. Вам нужно построить для него целую систему доверия.
А цена этой системы доверия — 510 тысяч строк кода.
Ссылка на оригинал
Нажмите, чтобы узнать о вакансиях в Invigorate BlockBeats
Добро пожаловать в официальное сообщество Invigorate BlockBeats:
Telegram канал подписки: https://t.me/theblockbeats
Telegram чат: https://t.me/BlockBeats_App
Twitter официальный аккаунт: https://twitter.com/BlockBeatsAsia
