Trade
Basic
Futures
Futures
Hundreds of contracts settled in USDT or BTC
TradFi
Gold
Trade global traditional assets with USDT in one place
Options
Hot
Trade European-style vanilla options
Unified Account
Maximize your capital efficiency
Demo Trading
Futures Kickoff
Get prepared for your futures trading
Futures Events
Participate in events to win generous rewards
Demo Trading
Use virtual funds to experience risk-free trading
Earn
Launch
CandyDrop
Collect candies to earn airdrops
Launchpool
Quick staking, earn potential new tokens
HODLer Airdrop
Hold GT and get massive airdrops for free
Launchpad
Be early to the next big token project
Alpha Points
Trade on-chain assets and enjoy airdrop rewards!
Futures Points
Earn futures points and claim airdrop rewards
Investment
Simple Earn
Earn interests with idle tokens
Auto-Invest
Auto-invest on a regular basis
Dual Investment
Buy low and sell high to take profits from price fluctuations
Soft Staking
Earn rewards with flexible staking
Crypto Loan
0 Fees
Pledge one crypto to borrow another
Lending Center
One-stop lending hub
VIP Wealth Hub
Customized wealth management empowers your assets growth
Private Wealth Management
Customized asset management to grow your digital assets
Quant Fund
Top asset management team helps you profit without hassle
Staking
Stake cryptos to earn in PoS products
Smart Leverage
New
No forced liquidation before maturity, worry-free leveraged gains
GUSD Minting
Use USDT/USDC to mint GUSD for treasury-level yields
More
Trending Topics
View More357.23K Popularity
22.99K Popularity
65.13K Popularity
16.05K Popularity
470.83K Popularity
Pin
ByteDance's new algorithm directly cuts off one-third of the computing power
Over the past two years, large language models have advanced at an incredible pace, especially in tasks requiring complex logical reasoning, reaching levels we previously wouldn’t have dared to imagine.
I still remember the era of ChatGPT-3.5. Back then, AI could at most help you solve simple math problems, write a few lines of basic code, and would get stuck on slightly more complicated questions. No internet search, let alone deep thinking. It answered every question based solely on the “stock” information stored during pretraining—once used up, it was gone.
But now, things are different. Models are beginning to learn how to break down problems themselves, step by step, generating extended chains of reasoning. They’ve even achieved jaw-dropping results in hardcore tasks like math competitions and programming challenges, making humans stare in disbelief.
However, the Scaling Law has brought about “miracles through great effort,” but also quietly buried a problem: overthinking.
Think back to two classic AI jokes that highlight this issue:
One is a test used in the US to measure AI IQ: “How many 'r’s are in the word ‘Strawberry’?” This is a question a preschooler can answer. But a year ago, ChatGPT got it wrong, DeepSeek got it wrong, and even Doubao got it wrong. Reasoning models like R1 would even spend ten minutes flipping back and forth, debating with themselves, and finally carefully tell you: two.
When AI finally fills this gap, a new question emerged from Chinese developers: if you need to go 50 meters to wash your car, should you drive or walk?
AI got confused again. Some answered “walk,” instantly; others calculated time, distance, and cost thoroughly, and still concluded: “walk.”
Moreover, the car-washing example reminds us that thinking longer doesn’t always mean thinking better. Sometimes, overthinking leads to getting tangled up in your own thoughts.
So, people are asking: does a super-capable model really need to think for so long? Does it know when to stop itself?
Recently, ByteDance and Beihang University published a paper specifically addressing this question.
01 Diagnosis: Where is the problem?
For AI companies, tokens are the most critical resource. Reducing unnecessary token consumption is equivalent to greatly lowering inference costs.
The research team found that the key issue lies in sampling strategies. Under current sampling paradigms, the model’s efficient reasoning ability cannot be fully utilized.
Typically, model evaluation uses a method called “Pass@1,” which only considers the first generated result to see if it passes the test case.
But in this sampling mode, explicit reasoning chains from models like DeepSeek show that: after arriving at the correct answer, the model usually doesn’t stop immediately and tell the user the answer. Instead, it continues generating a large amount of invalid verification or repetitive steps.
Let’s do a test: ask AI to compute the square of 20260226, emphasizing direct output of the result. DeepSeek took 38 seconds to produce the correct answer:
This is just a part of the explicit reasoning chain. In fact, during those 38 seconds, after getting the correct answer, the model still went through multiple useless verification steps—checking digit counts, carry errors, last digit verification, and so on.
This isn’t unique to DeepSeek. According to existing research, this counterintuitive phenomenon has been noticed:
Longer reasoning chains do not necessarily lead to higher accuracy; sometimes, shorter chains are more accurate.
For example, in the AIME 2025 benchmark, DeepSeek-R1’s responses are five times longer than Claude 3.7 Sonnet’s, yet their accuracy is similar.
Moreover, for the same model on the same question, 72% of longer responses are incorrect.
To systematically quantify this “overthinking” phenomenon, ByteDance and Beihang researchers defined a new metric:
First Correct Step Ratio (RFCS): = index of the step where the correct answer first appears / total reasoning steps.
For example, DeepSeek’s lightweight 1.5B model can find the correct answer on some questions with only 500 tokens, but due to current sampling strategies, it needs to generate an additional 452 redundant tokens to finish reasoning.
It appears that under current sampling paradigms, the model doesn’t know when to stop itself.
02 Surprising discovery: the model knows!
However, the research team found an counterintuitive fact:
If the sampling space is expanded to “Pass@K,” meaning generating K reasoning chains and checking if any produce a correct answer, the results are completely different.
To do this, the paper defines two metrics and a symbol:
Local Confidence (Next-token Probability): the probability of generating the next word;
Path Confidence (Cumulative Log-Probability, Φ): the average cumulative probability of generating the entire reasoning chain from start to finish;
End-of-Chain Token: the signal indicating the reasoning chain is complete.
If the model only uses local confidence to decide whether to output an end token “” and stop thinking, it always lacks confidence, because each next-word probability is higher than the probability of generating the end token.
Thus, the reasoning chain length keeps extending.
But if the model uses path confidence to decide when to stop, the situation is entirely reversed:
When the model has explored a very concise, correct reasoning chain and reaches the point to end, the probability of generating the end token surpasses other tokens, rising to the top, and the reasoning process ends smoothly.
This phenomenon is astonishing: the model is actually very confident that this concise reasoning chain is correct and wants to stop immediately.
Therefore, the model isn’t unaware of when to stop thinking; rather, short-sighted sampling strategies hide the model’s global reasoning potential.
03 SAGE Algorithm: Achieving Efficient Reasoning
After identifying the root cause and mechanism, the solution became clear.
The research shows that as long as the large model is given enough sampling space to explore multiple solutions freely, it can accurately select the “short and powerful” correct reasoning chain based on path confidence.
Based on this insight, ByteDance and Beihang team proposed SAGE Algorithm: Self-Aware Guided Efficient Reasoning.
Considering the high computational cost of token-level probability evaluation—requiring calculating probabilities for each token until the end-of-sequence token—SAGE adopts a “dimensionality reduction” approach, exploring at the step level:
For each step in the reasoning chain, SAGE uses underlying stochastic sampling to generate multiple complete reasoning steps;
Among these candidate branches, if any one ends with the end-of-chain token “”, SAGE immediately concludes: the model has thought it through and can stop.
This branch is then retained as a high-confidence result.
To illustrate SAGE’s effectiveness, the paper presents comparison experiments:
When the most intelligent model tackles the hardest math problems, SAGE helps it find shorter paths, significantly improving accuracy while avoiding hallucinations caused by lengthy reasoning.
For slightly weaker models on simpler datasets (like digit-letter problems), SAGE enables the model to stop quickly after finding the correct answer, greatly improving token efficiency.
The value of SAGE lies in its ability to:
Avoid manual truncation of reasoning, prevent meaningless chain extensions, and turn the model’s inherent “self-awareness” into actual reasoning efficiency.
04 SAGE-RL: Unlocking Commercial Value
While SAGE is very effective, it remains a reasoning-stage strategy.
Each inference still involves generating multiple reasoning branches, which incurs computational costs.
The algorithm itself is described in the paper; only when applied to real large models during training can it produce practical value.
Currently, the most advanced training method for reasoning models like DeepSeek is reinforcement learning based on verifiable rewards, exemplified by GRPO.
An example from the paper explains the standard GRPO training process:
Given a question, the model randomly generates 8 different answers, with correct ones rewarded, and the model’s weights are updated accordingly. The so-called “reward model” is used for this.
However, since these 8 answers are produced via standard stochastic sampling, the phenomenon of “overthinking” naturally occurs. The result is: the model can answer correctly but also learns to talk a lot of nonsense.
To incorporate SAGE, the team replaces part of the process:
Generate 8 answers, with 6 using original sampling, and 2 using SAGE.
We already know SAGE produces correct and concise answers. Although the reward mechanism doesn’t know which two answers are from SAGE, it tends to give them higher scores.
This cycle gradually makes the model favor SAGE-generated answers, and as the model updates, it corrects its tendency to overthink, gradually shifting its reasoning pattern toward the SAGE-efficient style.
Thus, SAGE becomes embedded in the model’s “DNA,” forming the basis of SAGE-RL.
Finally, the team evaluated SAGE-RL on six extremely challenging AI math benchmarks like MATH-500 and AIME 2025:
Existing methods to reduce reasoning length often sacrifice accuracy.
But SAGE-RL based on GRPO achieves “cost reduction and efficiency enhancement.”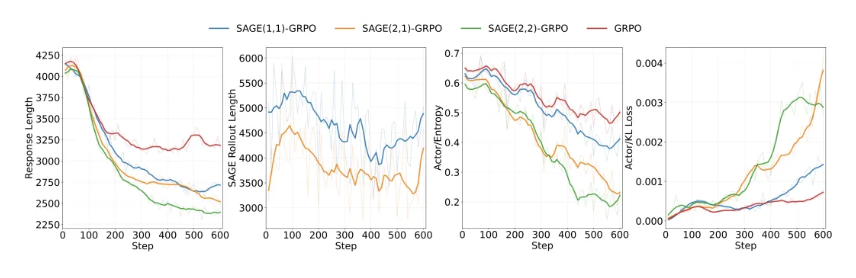 Tests on 7B models show that adding SAGE reduces average response length from 3219 tokens to 2141 tokens—about one-third less computation.
Tests on 7B models show that adding SAGE reduces average response length from 3219 tokens to 2141 tokens—about one-third less computation.
At the same time, the Pass@1 accuracy on MATH-500 increased from 92% to 93%, with token efficiency improving dramatically.
The earlier introduced RFCS metric also shows a significant drop in redundant steps, indicating the model has finally learned to “stop overthinking” and “know when to point directly.”
Currently, most AI companies charge via API, where increasing token output seems to boost revenue.
But top AI firms dream of reducing redundant token consumption. More concurrent requests processed per server yields higher profits than making each request verbose.
In real-world AI agent deployment, latency is a “kill switch.” Slow models can’t meet real-time user needs and will be abandoned.
DeepSeek shocked Silicon Valley a year ago, not only because they open-sourced powerful tech and advanced algorithms but also because they drastically lowered inference costs.
If existing models can’t change the current pattern of generating answers with massive redundancy, API costs will never come down.
Those who master efficient reasoning techniques like SAGE can achieve the same or higher accuracy with far less compute. In an environment where the marginal gains of increasing model intelligence diminish, this is the foundation for price wars and cost reductions.
In the future, large models won’t need to prove their intelligence with lengthy explanations. The highest form of intelligence is hidden in that perfect “pause” moment.
Source: Silicon Starshine
Risk Disclaimer
Market risks are present; investments should be cautious. This article does not constitute personal investment advice and does not consider individual users’ specific investment goals, financial situations, or needs. Users should evaluate whether any opinions, viewpoints, or conclusions herein are suitable for their circumstances. Invest at your own risk.