O desafio da stack de dados blockchain moderna
Uma startup moderna de indexação de blockchain enfrenta vários desafios, entre os quais se destacam:
- Volumes massivos de dados. À medida que a quantidade de dados na blockchain cresce, o índice de dados precisa de escalar para suportar o aumento da carga e garantir um acesso eficiente. Isto conduz a custos de armazenamento mais elevados, cálculos de métricas mais lentos e maior carga sobre o servidor de base de dados.
- Pipelines de processamento de dados complexos. A tecnologia blockchain é intrinsecamente complexa e criar um índice de dados fiável e abrangente exige profundo conhecimento das estruturas e algoritmos subjacentes. A diversidade de implementações blockchain acentua esta dificuldade. Por exemplo, os NFT em Ethereum são geralmente criados em smart contracts que seguem os formatos ERC721 e ERC1155, enquanto em Polkadot, por exemplo, a sua implementação é feita diretamente no runtime da blockchain. No final, todos devem ser considerados NFT e armazenados como tal.
- Capacidade de integração. Para maximizar o valor para o utilizador, uma solução de indexação blockchain pode ter de integrar o seu índice de dados com outros sistemas, como plataformas de análise ou APIs. Esta integração é desafiante e exige um desenho arquitetónico robusto.
Com a adoção generalizada da tecnologia blockchain, o volume de dados armazenados na blockchain aumentou significativamente. Isto resulta não só do maior número de utilizadores, mas também do facto de cada transação adicionar novos dados à cadeia. Além disso, o uso da blockchain evoluiu de simples transferências monetárias, como as associadas ao Bitcoin, para aplicações mais complexas com lógica de negócio implementada em smart contracts. Estes contratos inteligentes geram grandes volumes de dados, aumentando a complexidade e a dimensão da blockchain. Ao longo do tempo, isto resultou numa blockchain substancialmente maior e mais complexa.
Neste artigo, analisamos a evolução da arquitetura tecnológica da Footprint Analytics, utilizando-a como caso de estudo para demonstrar como a stack Iceberg-Trino responde aos desafios dos dados on-chain.
A Footprint Analytics já indexou cerca de 22 blockchains públicas, 17 marketplaces de NFT, 1900 projetos GameFi e mais de 100 000 coleções de NFT numa camada semântica de abstração de dados. É atualmente a solução de data warehouse blockchain mais abrangente a nível mundial.
No caso dos dados blockchain, que incluem mais de 20 mil milhões de linhas de registos de transações financeiras frequentemente analisados, o perfil difere substancialmente dos logs de entrada dos data warehouses tradicionais.
Nos últimos meses, realizámos três grandes atualizações para responder às crescentes exigências do negócio:
Arquitetura 1.0 Bigquery
Na fase inicial da Footprint Analytics, utilizámos o Google Bigquery como motor de armazenamento e consulta. O Bigquery é um produto de excelência: extremamente rápido, intuitivo e oferece capacidade aritmética dinâmica e uma sintaxe UDF flexível, permitindo-nos executar tarefas com grande rapidez.
No entanto, o Bigquery apresenta várias limitações.
- Os dados não são comprimidos, o que resulta em custos de armazenamento elevados, sobretudo no caso dos dados brutos das mais de 22 blockchains da Footprint Analytics.
- Concorrência insuficiente: o Bigquery suporta apenas 100 consultas simultâneas, o que é inadequado para os cenários de alta concorrência da Footprint Analytics, que serve muitos analistas e utilizadores.
- Dependência do Google Bigquery, um produto proprietário.
Por este motivo, decidimos explorar arquiteturas alternativas.
Arquitetura 2.0 OLAP
Demonstrámos grande interesse nos produtos OLAP que ganharam destaque no mercado. O principal atrativo do OLAP reside no tempo de resposta às consultas, que é normalmente inferior a um segundo para grandes volumes de dados e suporta milhares de consultas concorrentes.
Selecionámos uma das melhores bases de dados OLAP, a Doris, para avaliação. Este motor apresenta um desempenho sólido. Contudo, rapidamente surgiram outros desafios:
- Tipos de dados como Array ou JSON ainda não eram suportados (novembro de 2022). Arrays são comuns em algumas blockchains, como o campo topic nos logs EVM. A impossibilidade de cálculo direto sobre Array limita a nossa capacidade de calcular várias métricas de negócio.
- Suporte limitado ao DBT e a comandos merge. Estes são requisitos frequentes para engenheiros de dados em cenários ETL/ELT, onde é necessário atualizar dados recentemente indexados.
Assim, não foi possível utilizar o Doris em toda a pipeline de dados em produção, pelo que optámos por usá-lo como base OLAP para resolver parte do problema na produção de dados, atuando como motor de consulta e oferecendo capacidades de consulta rápidas e concorrentes.
Infelizmente, não conseguimos substituir o Bigquery pelo Doris, obrigando à sincronização periódica de dados do Bigquery para o Doris, utilizado apenas como motor de consulta. Este processo de sincronização revelou vários problemas, nomeadamente o rápido acumular de operações de escrita quando o motor OLAP estava ocupado a servir consultas ao front-end. Como consequência, o desempenho do processo de escrita degradava-se, a sincronização tornava-se muito mais demorada e, em alguns casos, impossível de concluir.
Concluímos que o OLAP resolvia vários problemas, mas não era a solução integral para a Footprint Analytics, especialmente ao nível do processamento de dados. O desafio era maior e mais complexo; o OLAP, apenas como motor de consulta, revelou-se insuficiente.
Arquitetura 3.0 Iceberg + Trino
Apresentamos a arquitetura 3.0 da Footprint Analytics, uma reformulação completa da infraestrutura subjacente. Redesenhámos a arquitetura de raiz, separando armazenamento, computação e consulta de dados em três componentes distintos. Retirámos lições das arquiteturas anteriores e aprendemos com a experiência de projetos de big data de referência, como Uber, Netflix e Databricks.
Introdução ao data lake
O primeiro passo foi direcionar a atenção para o data lake, uma solução de armazenamento para dados estruturados e não estruturados. O data lake é ideal para dados on-chain, pois os formatos variam amplamente, desde dados brutos não estruturados até abstrações estruturadas, pelas quais a Footprint Analytics é reconhecida. A expectativa era resolver o problema de armazenamento e garantir compatibilidade com motores de computação mainstream, como Spark e Flink, facilitando a integração com diferentes motores à medida que a Footprint Analytics evolui.
O Iceberg integra-se perfeitamente com Spark, Flink, Trino e outros motores de computação, permitindo-nos selecionar o motor mais adequado para cada métrica. Exemplos:
- Para lógica computacional complexa, utilizamos Spark.
- Para computação em tempo real, recorremos ao Flink.
- Para tarefas ETL simples executáveis em SQL, optamos pelo Trino.
Motor de consulta
Com o Iceberg a resolver o armazenamento e a computação, a escolha do motor de consulta tornou-se a prioridade seguinte. As opções consideradas foram:
- Trino: motor de consulta SQL
- Presto: motor de consulta SQL
- Kyuubi: Spark SQL serverless
O critério fundamental foi garantir compatibilidade com a arquitetura existente.
- Suporte ao Bigquery como fonte de dados
- Compatibilidade com DBT, essencial para a produção de várias métricas
- Integração com a ferramenta BI Metabase
Com base nestes requisitos, optámos pelo Trino, que oferece excelente integração com o Iceberg e uma equipa de suporte altamente reativa: após reportarmos um bug, este foi corrigido no dia seguinte e lançado na versão mais recente na semana seguinte. Esta foi, sem dúvida, a melhor escolha para a equipa da Footprint, que exige elevada capacidade de resposta.
Testes de desempenho
Após definir a estratégia, realizámos testes de desempenho à combinação Trino + Iceberg para avaliar se cumpria os requisitos — e, para nossa surpresa, as consultas foram excecionalmente rápidas.
Sendo o Presto + Hive tradicionalmente o pior comparativo no universo OLAP, a combinação Trino + Iceberg superou todas as expectativas.
Apresentamos os resultados dos testes:
caso 1: junção de grandes conjuntos de dados
Uma tabela1 de 800 GB faz join com uma tabela2 de 50 GB e executa cálculos de negócio complexos
caso 2: consulta distinct numa tabela de grande dimensão
SQL de teste: select distinct(address) from table group by day

A combinação Trino+Iceberg é aproximadamente três vezes mais rápida do que o Doris nas mesmas condições.
Além disso, o Iceberg suporta formatos de dados como Parquet e ORC, que comprimem e armazenam os dados. O armazenamento de tabelas no Iceberg ocupa apenas cerca de 1/5 do espaço de outros data warehouses. Eis a comparação do espaço ocupado pela mesma tabela nas três bases de dados:

Nota: Os testes acima são exemplos reais de produção e servem apenas de referência.
・Efeito da atualização
Os relatórios de desempenho deram-nos confiança para concluir a migração em cerca de dois meses. Segue-se o diagrama da arquitetura após a atualização.
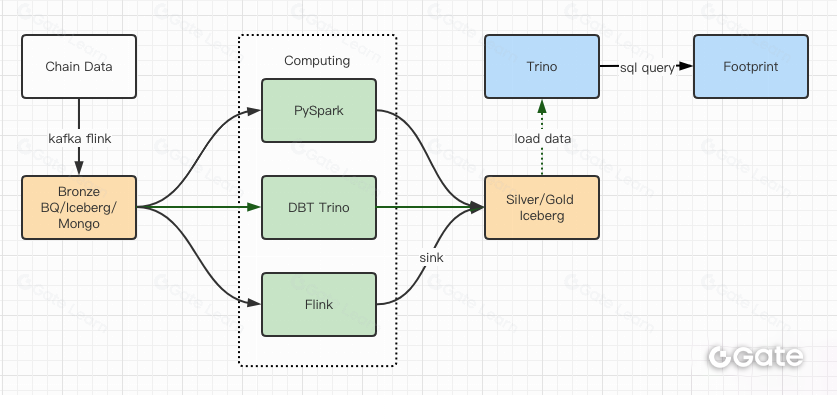
- Vários motores de computação adaptam-se às nossas necessidades.
- O Trino suporta DBT e consulta diretamente o Iceberg, eliminando a necessidade de sincronização de dados.
- O desempenho excecional do Trino + Iceberg permite disponibilizar todos os dados Bronze (dados brutos) aos utilizadores.
Resumo
Desde o lançamento em agosto de 2021, a equipa da Footprint Analytics realizou três upgrades arquiteturais em menos de um ano e meio, graças à ambição e determinação em disponibilizar a melhor tecnologia de base de dados aos seus utilizadores cripto, aliadas a uma execução sólida na implementação e atualização de infraestrutura e arquitetura.
O upgrade arquitetural 3.0 da Footprint Analytics proporcionou uma experiência renovada, permitindo a utilizadores de diferentes perfis aceder a perspetivas em contextos e aplicações mais diversos:
- Com a ferramenta BI Metabase, a Footprint permite aos analistas aceder a dados on-chain descodificados, explorar livremente com qualquer ferramenta (no-code ou hardcode), consultar todo o histórico e cruzar conjuntos de dados para obter perspetivas em tempo recorde.
- Integra dados on-chain e off-chain para análise cruzada entre web2 e web3;
- Ao construir ou consultar métricas sobre a abstração de negócio da Footprint, analistas e developers poupam tempo em 80% do processamento repetitivo de dados e podem focar-se em métricas relevantes, investigação e soluções de produto ajustadas ao negócio.
- Experiência fluida desde a Footprint Web até às chamadas REST API, tudo baseado em SQL
- Alertas em tempo real e notificações acionáveis sobre sinais-chave para apoiar decisões de investimento