En bref
- Un développeur a découvert que forcer Claude à parler comme un homme des cavernes réduit fortement le nombre de tokens de sortie, et donc les coûts, jusqu’à 75%.
- Internet s’en est immédiatement servi comme d’une compétence GitHub.
- Avec Anthropic qui facture si cher par token de sortie, le mode grun-mode est moins une blague et davantage une stratégie budgétaire.
Quelque part entre l’ingénierie de prompt et l’art de la performance, un développeur a posté sur Reddit une découverte qui a fait rire la communauté IA avant même qu’elle ne s’y intéresse : apprendre à Claude à communiquer comme un humain préhistorique et regarder la facture de tokens diminuer jusqu’à 75%.
Le post a touché r/ClaudeAI la semaine dernière et, depuis, a accumulé plus de 400 commentaires et 10K votes — une combinaison rare d’insight technique réel et de comédie absurde, que l’internet a tendance à récompenser.

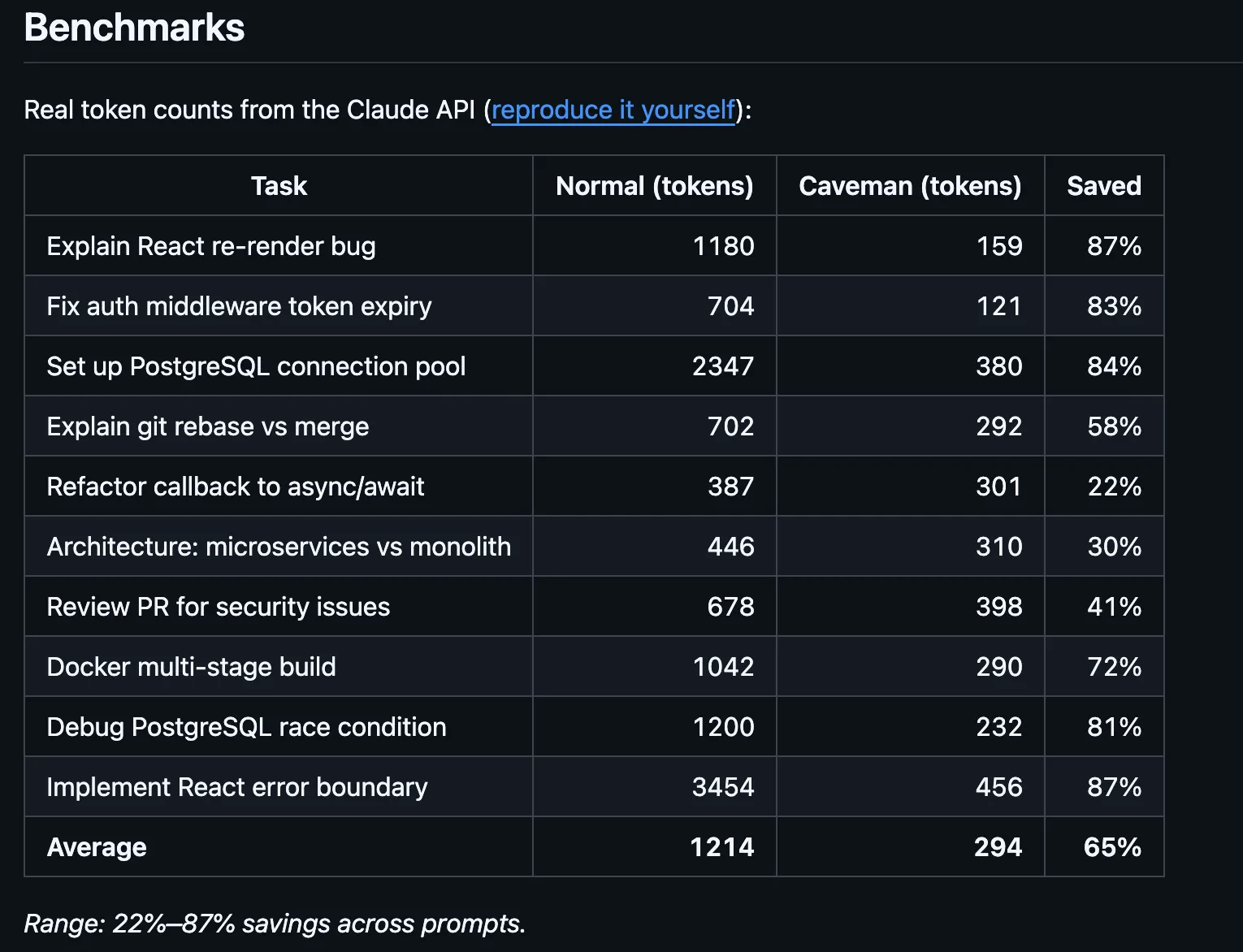
Le mécanisme est simple. Au lieu de laisser Claude se réchauffer avec des politesses, racontez chaque étape qu’il effectue, puis terminez par une proposition pour aider davantage ; ainsi, le développeur contraint le modèle à des phrases courtes, épurées. D’abord l’outil, d’abord le résultat, pas d’explication. Une tâche de recherche web normale qui tournerait environ 180 tokens de sortie est tombée à environ 45. L’auteur original affirme jusqu’à 75% de réduction de la sortie, obtenue en faisant sonner le modèle comme s’il venait juste de découvrir le feu.
En termes d’homme des cavernes, comme l’a dit un redditeur : « Pourquoi perdre du temps à dire beaucoup de mots quand peu de mots font l’affaire ? »
Ce que cette technique ne touche pas, c’est le contexte en entrée : l’historique complet de la conversation, les fichiers joints et les instructions système que le modèle relit à chaque tour. Cette entrée dépasse typiquement la sortie, surtout dans des sessions de codage plus longues. En comptant tout cela dans des sessions réelles, les économies sont d’environ 25%, pas 75%. Cela reste significatif, juste pas le chiffre mis en avant.
Il est aussi une bonne idée d’alimenter le modèle avec des instructions normales. Ne lui donnez pas la discussion « homme des cavernes », car elle pourrait déraper vers une situation du type « garbage in, garbage out ».
Il y a aussi la question de la dégradation de l’intelligence. Quelques chercheurs dans le fil ont fait valoir que forcer une IA à habiter une personnalité moins sophistiquée pourrait nuire activement à sa qualité de raisonnement — que les contraintes verbales pourraient déborder dans le cognitif. La question n’a pas été tranchée de façon définitive, mais elle mérite d’être prise en compte lors de l’évaluation des résultats.
Compétence bien, la compétence devient virale
Malgré les réserves, la technique a trouvé une deuxième vie sur GitHub presque immédiatement.
Le développeur Shawnchee a emballé les règles dans une compétence autonome compatible avec Claude Code, Cursor, Windsurf, Copilot et plus de 40 autres agents. La compétence distille l’approche en 10 règles : pas de phrases inutiles, exécuter avant d’expliquer, pas de méta-commentaire, pas de préambule, pas de postambule, pas d’annonces d’outils, expliquer seulement quand c’est nécessaire, laisser le code parler pour lui, et traiter les erreurs comme des choses à corriger plutôt que comme des récits.
Des benchmarks dans le dépôt, vérifiés avec tiktoken, montrent des réductions de tokens de sortie de 68% sur des tâches de recherche web, 50% sur des modifications de code, et 72% sur des échanges question-réponse — pour une réduction moyenne de la sortie de 61% sur quatre tâches standard.
Un dépôt parallèle du développeur Julius Brussee a adopté une approche légèrement différente, en présentant la même idée comme un fichier SKILL.md avec 562 stars sur GitHub. La spécification : répondre comme un homme des cavernes intelligent, couper les articles, les éléments de remplissage et les politesses ; garder toute la substance technique. Les blocs de code restent inchangés. Les messages d’erreur sont cités exactement. Les termes techniques restent intacts. L’homme des cavernes ne parle que de l’habillage anglais autour des faits.
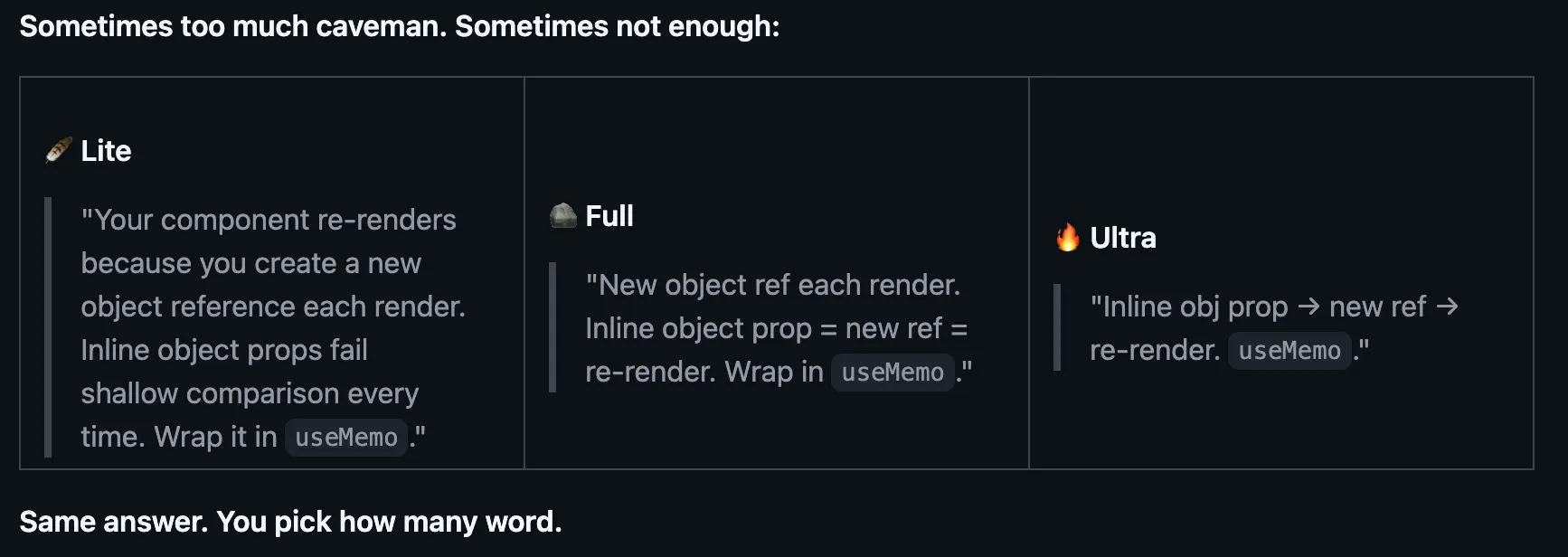
Celui-ci est même livré avec différents modes pour affecter la quantité que vous voulez réduire, en passant entre Normal, Lite et Ultra. Les modèles font exactement le même travail, mais fournissent une réponse beaucoup plus courte, ce qui génère une grosse économie au fil du temps.
Le contexte plus large des coûts donne à la blague un tranchant plus vif. Anthropic fait partie des modèles les plus chers en termes de prix par token. Pour les développeurs qui exécutent des workflows agentic avec des dizaines de tours par session, la verbosité en sortie n’est pas un simple reproche de style. C’est une ligne budgétaire. Si un grognement d’homme des cavernes peut remplacer un résumé en cinq phrases de ce que le modèle vient de faire, alors les tokens économisés s’accumulent sur des milliers d’appels API.
La compétence homme des cavernes est installable en une commande via skills.sh et fonctionne globalement sur des projets. Que cela rende Claude légèrement moins articulé ou non, cela a déjà rendu beaucoup de développeurs significativement moins agacés.
Avertissement : Les informations contenues dans cette page peuvent provenir de tiers et ne représentent pas les points de vue ou les opinions de Gate. Le contenu de cette page est fourni à titre de référence uniquement et ne constitue pas un conseil financier, d'investissement ou juridique. Gate ne garantit pas l'exactitude ou l'exhaustivité des informations et n'est pas responsable des pertes résultant de l'utilisation de ces informations. Les investissements en actifs virtuels comportent des risques élevés et sont soumis à une forte volatilité des prix. Vous pouvez perdre la totalité du capital investi. Veuillez comprendre pleinement les risques pertinents et prendre des décisions prudentes en fonction de votre propre situation financière et de votre tolérance au risque. Pour plus de détails, veuillez consulter l'
avertissement.
