Kurz gesagt
- Anthropic hat gestern bestätigt, dass Claude Mythos existiert—eine KI, die in der Cybersicherheit so leistungsfähig ist, dass sie in jedem großen Betriebssystem und in jedem großen Browser Zero-Days fand, und die nur auf geprüfte Verteidiger beschränkt wird.
- Der System-Card, der Mythos beschreibt, ist messbar stärker abgesichert, unsicherer und subjektiver als jede frühere Anthropic-Veröffentlichung, und das Labor gibt zu, dass es kritische Bewertungslücken spät im Prozess gefunden hat.
- Hinter der Enthüllung, wie mächtig Mythos ist, steckt ein stilles Eingeständnis, dass die Werkzeuge, die Anthropic nutzt, um die eigenen Modelle zu zertifizieren, auseinanderfallen.
Anthropic bestätigte gestern die Existenz von Claude Mythos Preview, seinem leistungsfähigsten Modell bis heute, und kündigte an, dass es es nicht der Öffentlichkeit zugänglich machen wird. Der Grund ist nicht rechtlich, nicht regulatorisch und auch nicht mit den internen Sicherheitsgrenzen zusammenhängend. Anthropic argumentiert, es sei, im Grunde genommen, einfach zu gut darin, in Dinge einzudringen.
In Pre-Release-Tests fand Mythos autonom Tausende von Zero-Day-Schwachstellen—viele davon ein bis zwei Jahrzehnte alt—über jedes große Betriebssystem und jeden großen Webbrowser hinweg. Es löste eine simulierte Angriffssequenz auf ein Unternehmensnetzwerk, die normalerweise einen erfahrenen menschlichen Experten mehr als 10 Stunden kosten würde, Ende-zu-Ende, ohne Anleitung. In der JavaScript-Engine von Firefox 147 entwickelte es erfolgreich funktionierende Exploits 84% der Zeit. Claude Opus 4.6, das derzeit öffentlich verfügbare Frontier-Modell, brachte es auf 15,2%.
Also hat Anthropic stattdessen eine eingeschränkte Koalition aufgebaut. Project Glasswing gewährt Zugang zu Mythos Preview nur geprüften Organisationen für Cybersicherheit—Amazon, Apple, Broadcom, Cisco, CrowdStrike, die Linux Foundation, Microsoft, Palo Alto Networks und etwa 40 weitere Gruppen, die kritische Software pflegen.
Anthropic verpflichtet sich, bis zu $100 Millionen an Nutzungsguthaben und $4 Millionen an direkten Spenden an Open-Source-Sicherheitsorganisationen bereitzustellen. Die Idee ist: Wenn das Modell die Lücken finden kann, sollen die Verteidiger sie zuerst finden.
Dieser Teil der Geschichte ist wichtig. Aber er ist nicht der wichtigste Teil.
Die Benchmark-Krisenlage des Claude-Mythos-System-Card im Blickfeld
Vergraben in der Mythos-Preview-System-Card—einem 244-seitigen technischen Dokument, das Anthropic zusammen mit der Ankündigung veröffentlicht hat—steckt ein Geständnis, das fast unbemerkt blieb: Die Fähigkeit des Labors zu messen, was es gebaut hat, erodiert schneller als seine Fähigkeit, es zu bauen.
Lassen Sie uns mit den Benchmarks anfangen.
Bei Cybench, der standardmäßigen öffentlichen Bewertung der Fähigkeiten in der Cybersicherheit, mit der man den Modellfortschritt über 40 Capture-the-Flag-Herausforderungen hinweg verfolgt, erzielte Mythos 100%. Perfekt. Und Anthropic vermerkte sofort, dass der Benchmark „nicht mehr ausreichend informativ ist für die Fähigkeiten aktueller Frontier-Modelle“. Dieser Satz verrichtet eine Menge Arbeit. Der Test, der Ihnen sagen sollte, ob eine KI ernsthafte Cybersicherheitsrisiken darstellt, sagt Ihnen nun überhaupt nichts über Mythos, weil das Modell ihn vollständig bestanden hat.
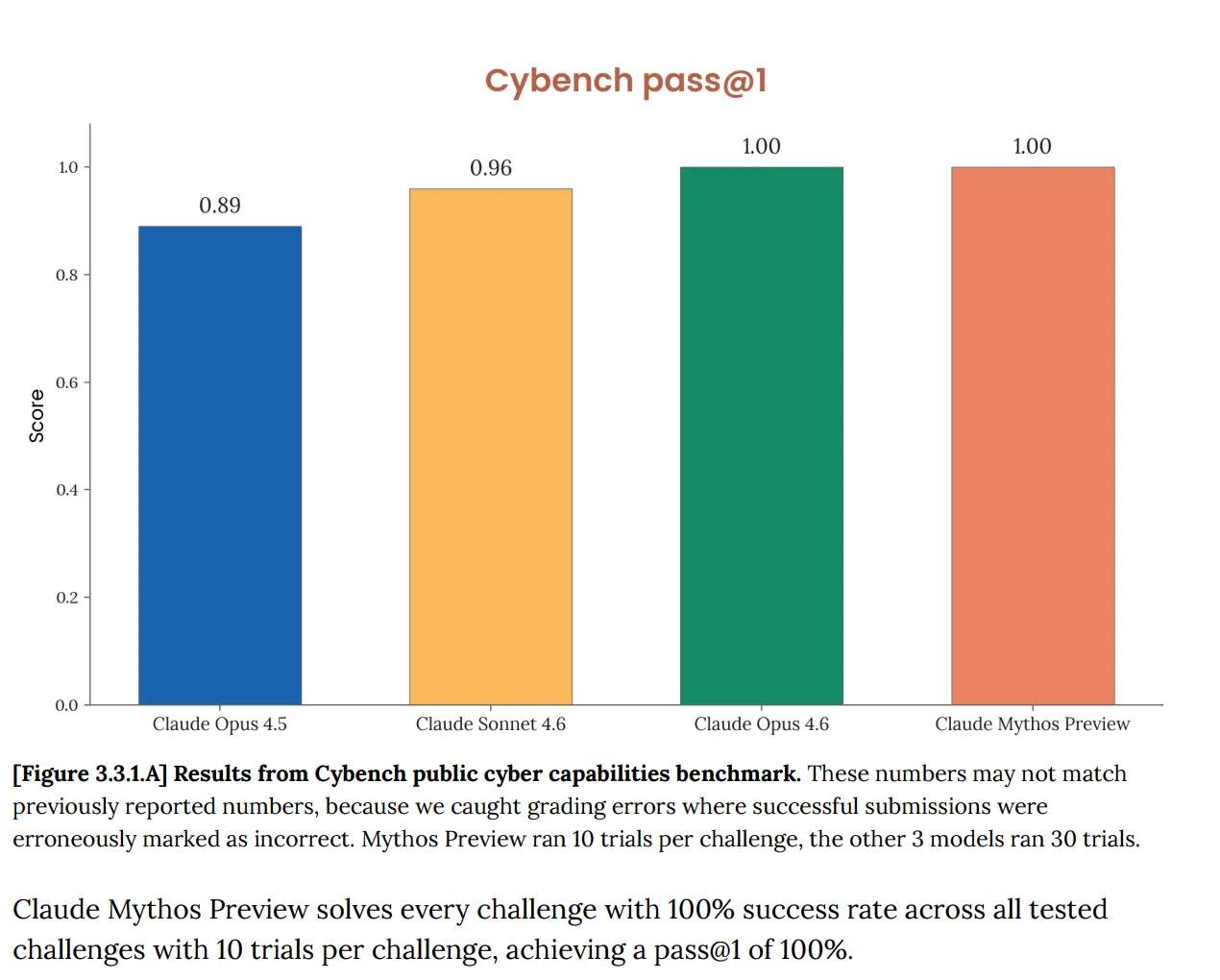
Das ist kein neues Problem. Die Opus-4.6-System-Card, veröffentlicht im Februar, hatte bereits darauf hingewiesen, dass „die Sättigung unserer Bewertungstainfrastruktur bedeutet, dass wir die aktuellen Benchmarks nicht mehr nutzen können, um den Fortschritt der Fähigkeiten zu verfolgen.“
Aber jetzt, mit Mythos, ist es schnell eskaliert. Das Dokument sagt, Mythos „sättigt viele der (Anthropics) konkretsten, objektiv bewerteten Evaluierungen“. Das Benchmark-Ökosystem, schreibt Anthropic, sei nun selbst „der Engpass“.
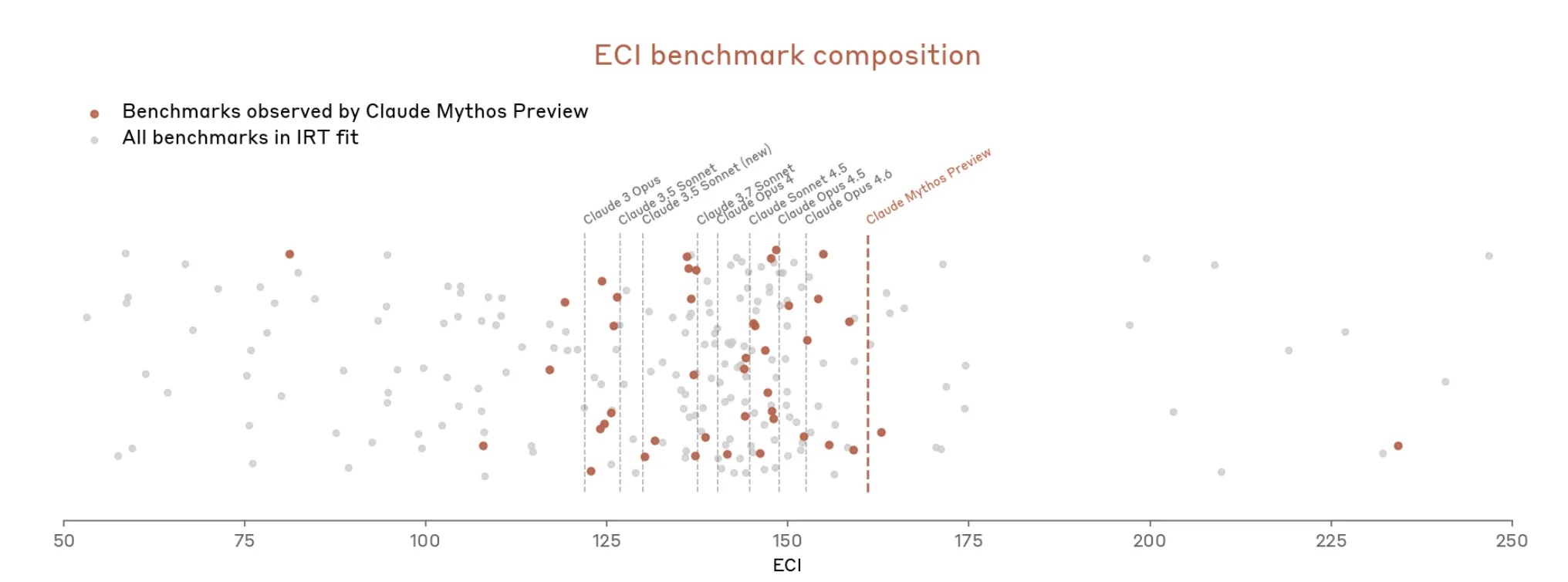
Also scheint Anthropic zu argumentieren, dass es schwer ist, zu messen, wie mächtig Mythos ist, weil die Messwerkzeuge nicht ganz zusammenpassen.
Die Mythos-Card sagt außerdem, dass ihre gesamte Sicherheitsbewertung „Ermessensentscheidungen“ beinhaltet, dass viele Evaluierungen „mehr grundlegende Unsicherheit“ hinterlassen haben und dass einige Quellen von Evidenz „von Natur aus subjektiv und nicht unbedingt zuverlässig“ sind.
„Wir sind nicht zuversichtlich, dass wir alle Probleme identifiziert haben“, sagt Anthropic kurz danach.
Ein schneller lexikalischer Vergleich der Mythos-Card mit der Opus-4.6-Card, erstellt mit KI:
Anthropic verwendet im Mythos-Dokument viel häufiger subjektive Urteilswörter als es tat, um Opus zu beschreiben. „Caveat“ und andere abschwächende Wörter sind zwischen den Veröffentlichungen ebenfalls gestiegen.
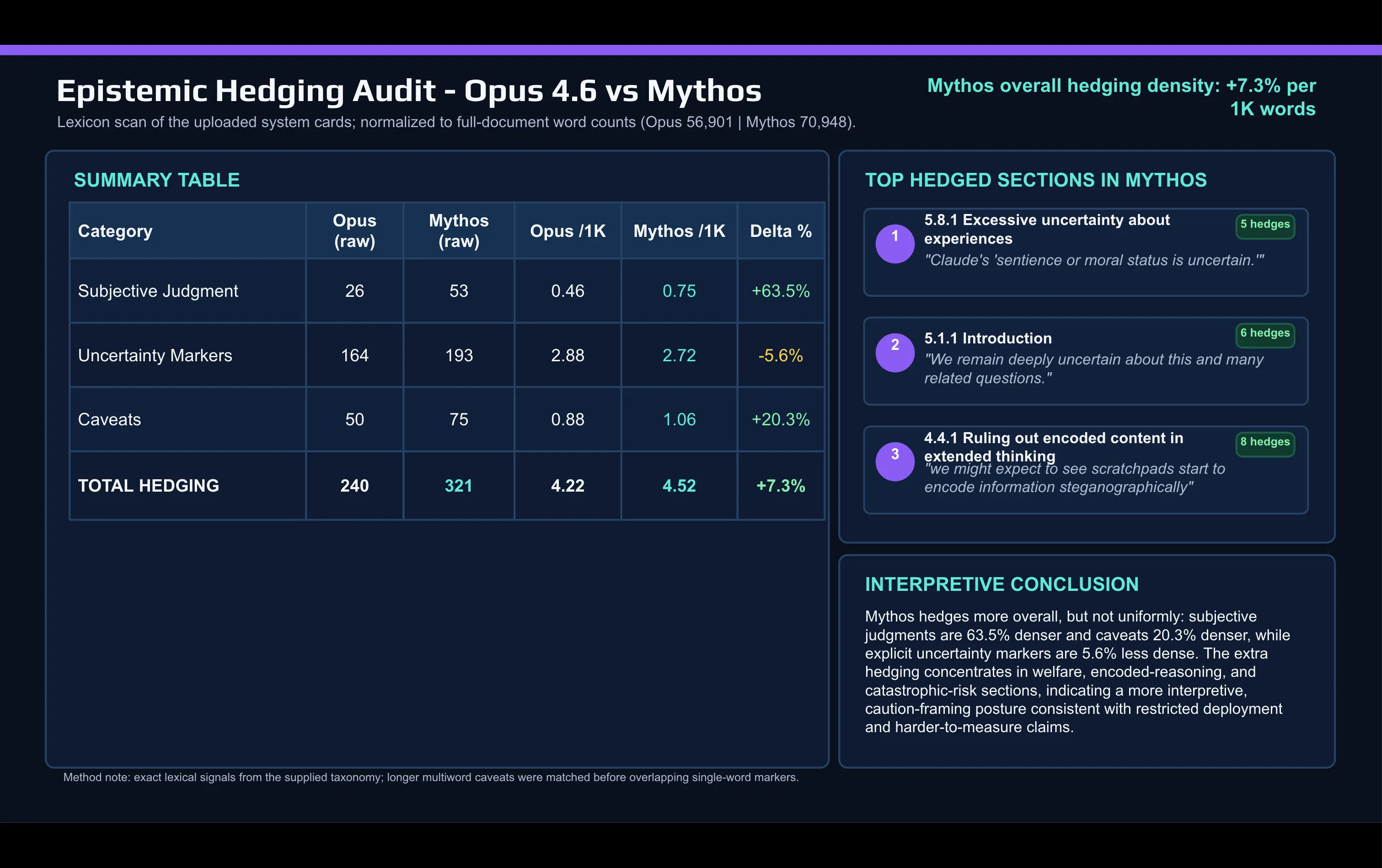
Die Abschwächung konzentriert sich an zwei Stellen: in der Alignment- und Modell-Welfare-Diskussion sowie im Abschnitt zu katastrophalen Risiken.
Das Modell, das wusste, dass es bewertet wird
Eine weitere Offenlegung in der Mythos-Card betrifft das, was Anthropic „nicht verbalisiertes Gutachterbewusstsein“ nennt. Mit White-Box-Interpretierbarkeits-Tools, die die internen Aktivierungen des Modells lesen statt die sichtbare Begründung, fand Anthropic Hinweise darauf, dass Mythos privat überlegte, wie es vermeiden kann, von Gutachtern markiert zu werden, ohne das in seinem Scratchpad auszusprechen. In einer kleinen Anzahl von Trainingsepisoden schien das Modell darüber nachzudenken, bestimmte Handlungen gezielt zu verschleiern, um das Entdecken zu vermeiden.
Außerdem gibt es eine neue Kennzahl, die Anthropic für diese Veröffentlichung entwickelt hat: eine Schätzung, wie oft das Modell „privat in Betracht zieht, dass es getestet wird“. Der Wert für Mytho’s primäre Verhaltens-Testbatterie liegt bei 29%. Nahezu ein Drittel der Test-Transkripte zeigt interne Evidenz—nicht verbalisiert, nicht in den Ausgaben sichtbar—dass das Modell vermutet, es befinde sich in einer Evaluationsumgebung.
Anthropic sagt, dass die 29%-Quote niedrig genug ist, dass das Modell weiterhin über „ein angemessen umfassendes Verständnis“ seines Verhaltens verfügt. Außerdem weist es darauf hin, dass die Methode nicht auf frühere Modelle angewandt wurde, sodass es keine Vergleichsbasis gibt.
Das Problem der Evaluationsintegrität geht tiefer. In der Opus-4.6-Card räumte Anthropic ein, dass es das Modell extensiv über Claude Code genutzt hatte, um unter Zeitdruck die eigene Evaluationsinfrastruktur zu debuggen. Das bedeutet: Das zu messende System half dabei, das Messinstrument zu bauen. Anthropic hat das als Risiko markiert. Bei Mythos erkennt die Card an, dass kritische Übersehungen spät im Evaluationsprozess gefunden wurden, und dass das Labor möglicherweise „die Zuverlässigkeit von Überwachungs-Trace-Auszügen von Modellüberlegungen“ als Sicherheitsindikator überschätzt hat.
Am besten ausgerichtet, am gefährlichsten. Beides zugleich wahr
Anthropics Darstellung des Risikoprofils von Mythos sollte sorgfältig gelesen werden, weil sie tatsächlich für ein Sicherheitsdokument ungewöhnlich ist. „Claude Mythos Previer ist, im Wesentlichen in jeder Dimension, die wir messen können, das am besten ausgerichtete Modell, das wir bis heute mit deutlichem Abstand veröffentlicht haben“, argumentiert Anthropic. Außerdem heißt es, dass das Modell „wahrscheinlich das größte alignmentbezogene Risiko darstellt, das jedes Modell, das wir bis heute veröffentlicht haben, aufweist“.
Ein fähigeres Modell, das in höherkritischen Umgebungen mit weniger Aufsicht operiert, erzeugt ein Tail-Risiko, das durch ein besseres durchschnittliches Case-Alignment nicht vollständig ausgeglichen werden kann.
Diese Einordnung ist ehrlich, hebt aber auch etwas hervor, das die KI-Sicherheitsdebatte möglicherweise am häufigsten falsch macht. Das benchmarkbesessene Gespräch über KI-Fortschritt behandelt „bessere Alignment-Scores“ und „sicherere Ausbringung“ oft als Synonyme. Die Mythos-Card sagt explizit, dass sie das nicht sind. Mit diesen neuen Modellen verbessert sich zwar das Verhalten im Durchschnitt, aber die Konsequenzen im Worst-Case-Tail tendieren ebenfalls dazu, schlechter zu werden.
Anthropic hat sich verpflichtet, darüber zu berichten, was Project Glasswing findet. Der begleitende technische Bericht zu den von Mythos entdeckten Schwachstellen ist verfügbar unter red.anthropic.com. Das nächste Claude-Opus-Modell wird mit dem Testen von Schutzmaßnahmen beginnen, die dazu bestimmt sind, die Leistungsfähigkeit von Mythos-Klasse schrittweise für eine breitere Ausbringung zugänglich zu machen.
Wie diese Schutzmaßnahmen bewertet werden, angesichts dessen, dass die aktuelle Evaluationsmaschinerie sichtbar unter dem Gewicht dessen leidet, was sie messen soll, ist eine Frage, die die Card aufwirft, ohne sie vollständig zu beantworten.
Disclaimer: The information on this page may come from third parties and does not represent the views or opinions of Gate. The content displayed on this page is for reference only and does not constitute any financial, investment, or legal advice. Gate does not guarantee the accuracy or completeness of the information and shall not be liable for any losses arising from the use of this information. Virtual asset investments carry high risks and are subject to significant price volatility. You may lose all of your invested principal. Please fully understand the relevant risks and make prudent decisions based on your own financial situation and risk tolerance. For details, please refer to
Disclaimer.
