باختصار
- يكشف ARC-AGI-3 عن فجوة هائلة بين ادعاءات الذكاء الاصطناعي العام والواقع، حيث تتجاوز نتائج أفضل نماذج الذكاء الاصطناعي 1% بينما يحقق البشر أداءً مثاليًا.
- الاختبار يقيس التعميم الحقيقي—مطلوب من الوكلاء استكشاف، وتخطيط، والتعلم من الصفر في بيئات غير معروفة بدلاً من استرجاع أنماط مدربة مسبقًا.
- على الرغم من الضجة الصناعية، لا تزال أنظمة الذكاء الاصطناعي الحالية بعيدة عن الذكاء الاصطناعي العام، وتفتقر إلى القدرة على التفكير والتكيف التي يظهرها البشر الصغار بشكل طبيعي.
قال جيفن هوانج، الرئيس التنفيذي لشركة Nvidia، في بودكاست ليكس فريدمن الأسبوع الماضي، بصراحة، “أعتقد أننا حققنا الذكاء الاصطناعي العام.” وبعد يومين، أُطلق أحدث اختبار للذكاء الاصطناعي في أبحاث الذكاء الاصطناعي—وكل النماذج المتقدمة سجلت أقل من 1%.
أطلقت مؤسسة جائزة ARC الأسبوع الماضي نسخة ARC-AGI-3، وكانت النتائج قاسية. تصدرت Google Gemini 3.1 Pro النتائج بنسبة 0.37%. وجاءت GPT-5.4 من OpenAI بنسبة 0.26%. وحققت Claude Opus 4.6 من Anthropic نسبة 0.25%، بينما سجلت Grok-4.20 من xAI صفرًا تمامًا. في المقابل، حلّ البشر 100% من البيئات.
هذا ليس اختبار معلومات عامة أو اختبار برمجة، أو حتى أسئلة صعبة جدًا على مستوى الدكتوراه. ARC-AGI-3 شيء مختلف تمامًا عن أي شيء واجهته صناعة الذكاء الاصطناعي من قبل.
تم بناء الاختبار بواسطة مؤسسة فرانسوا شوليه ومايك كنوب، التي أنشأت استوديو ألعاب داخليًا وابتكرت 135 بيئة تفاعلية أصلية من الصفر. الفكرة هي إدخال وكيل ذكاء اصطناعي إلى عالم يشبه اللعبة غير مألوف، بدون تعليمات، أو أهداف معلنة، أو وصف للقواعد. يجب على الوكيل استكشاف، وفهم ما يُطلب منه، وتشكيل خطة، وتنفيذها.
إذا بدا لك أن هذا شيء يمكن لأي طفل يبلغ من العمر خمس سنوات القيام به، فبدأت تفهم المشكلة. وإذا أردت أن تعرف إذا كنت أفضل من الذكاء الاصطناعي، يمكنك لعب نفس الألعاب التي تظهر في الاختبار عبر النقر على هذا الرابط. جربنا واحدة؛ كانت غريبة في البداية، لكن بعد بضع ثوانٍ، يمكنك بسهولة فهمها.
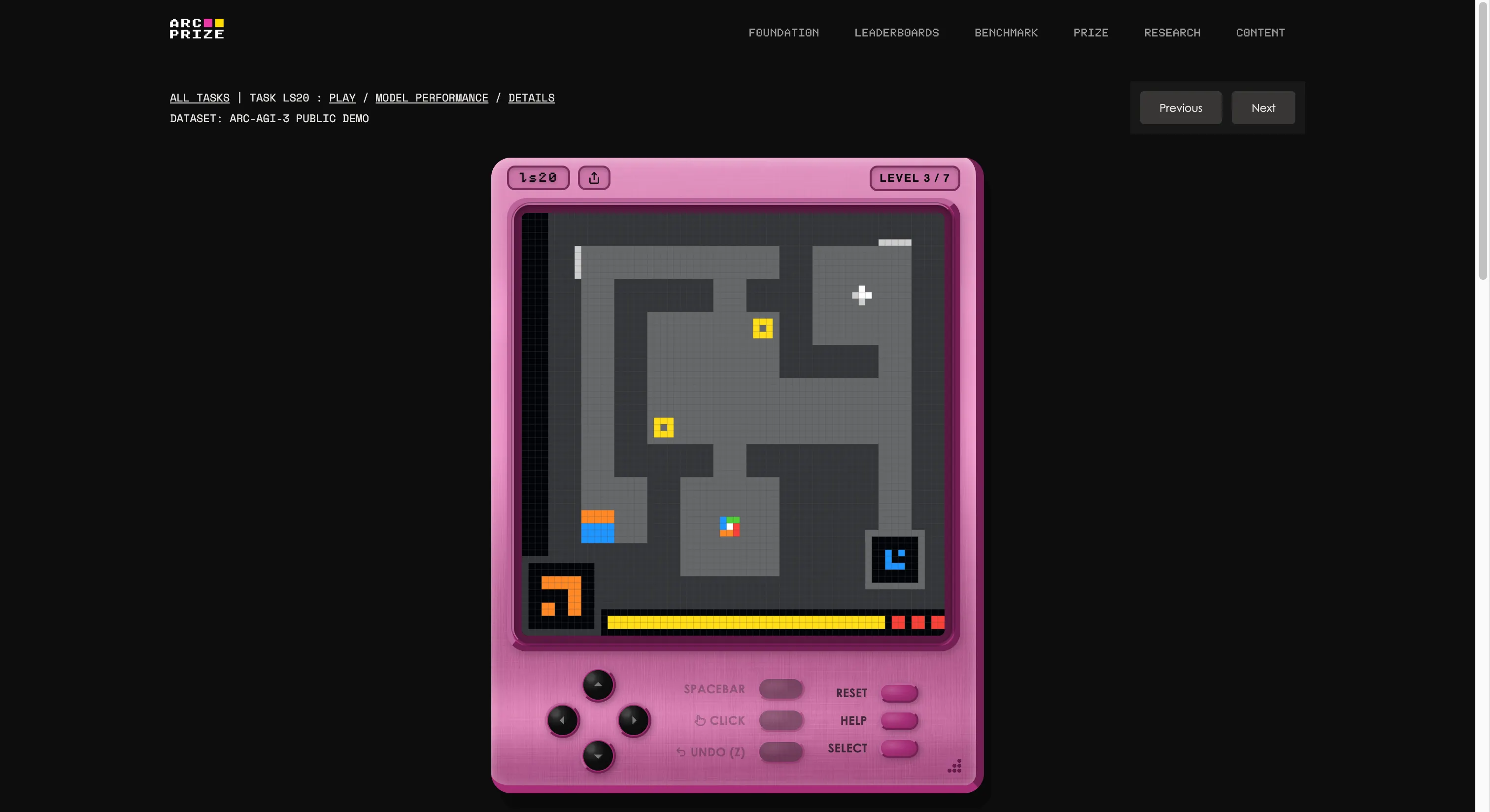
كما أنها المثال الأوضح على ما يعنيه حرف “G” في الذكاء الاصطناعي العام. عندما تعمم، تكون قادرًا على إنشاء معرفة جديدة (كيف يعمل لعبة غريبة) دون أن يتم تدريبك عليها مسبقًا.
الإصدارات السابقة من ARC كانت تختبر الأحاجي البصرية الثابتة—عرض نمط، وتوقع النمط التالي. كانت صعبة في البداية. ثم استثمرت المختبرات قوة الحوسبة والتدريب عليها حتى أصبحت الاختبارات غير ذات فائدة تقريبًا. ARC-AGI-1، الذي أُطلق في 2019، تراجع إلى نماذج تعتمد على تدريب وقت الاختبار والاستنتاج. استمر ARC-AGI-2 حوالي سنة قبل أن تصل Gemini 3.1 Pro إلى 77.1%. المختبرات جيدة جدًا في استغلال الاختبارات التي يمكنها تدريبها عليها.
تم تصميم النسخة 3 خصيصًا لمنع ذلك. مع إبقاء 110 من أصل 135 بيئة خاصة—55 شبه خاصة للاختبار عبر API، و55 مغلقة تمامًا للمنافسة—لا يوجد مجموعة بيانات للحفظ. لا يمكنك استخدام القوة الغاشمة لتجاوز منطق لعبة جديد لم تره من قبل.
التقييم ليس نجاحًا أو فشلًا أيضًا. يستخدم ARC-AGI-3 ما تسميه المؤسسة بـ RHAE—كفاءة العمل البشري النسبي. المعيار هو الأداء البشري الثاني الأفضل في أول محاولة. الذكاء الاصطناعي الذي يتطلب عشرة أضعاف الإجراءات التي يتطلبها الإنسان يحصل على 1% لهذا المستوى، وليس 10%. المعادلة تربع العقوبة على عدم الكفاءة. التجول، والتراجع، والتخمين للوصول إلى حل يعاقب بشدة.
أفضل وكيل ذكاء اصطناعي في معاينة المطورين التي استمرت شهرًا حقق 12.58%. نماذج اللغة المتقدمة التي تم اختبارها عبر API الرسمي، بدون أدوات مخصصة، لم تتجاوز 1%. حلّ البشر العاديون جميع البيئات الـ135 بدون تدريب مسبق وبدون تعليمات. إذا كان هذا هو المعيار، فإن النماذج الحالية لا تتجاوزه.
هناك جدل منهجي حقيقي هنا. تقول تقرير ARC إن منصة مخصصة من Duke دفعت Claude Opus 4.6 من 0.25% إلى 97.1% في نسخة واحدة من البيئة تسمى TR87. هذا لا يعني أن Claude حقق 97.1% على ARC-AGI-3 بشكل عام؛ بقيت نتيجته الرسمية 0.25%، لكن التغير لا يزال ملحوظًا.
الاختبار الرسمي يمد الوكلاء برمز JSON، وليس بصور مرئية. إما أن يكون ذلك عيبًا منهجيًا أو دليلًا على أن نماذج اليوم أفضل في معالجة المعلومات المفهومة للبشر من البيانات المنظمة الخام. اعترفت مؤسسة شوليه بالنقاش، لكنها لا تنوي تغيير التنسيق.
“تصور محتوى الإطار وتنسيق API ليسا عاملين مقيدين لأداء النماذج المتقدمة على ARC-AGI-3،” تقول الورقة. بمعنى آخر، يرفضون فكرة أن النماذج تفشل لأنها “لا تستطيع رؤية” المهام بشكل صحيح، ويؤكدون أن الإدراك كافٍ بالفعل، وأن الفجوة الحقيقية تكمن في التفكير والتعميم.
وصلت مراجعة واقع الذكاء الاصطناعي العام خلال أسبوع كانت فيه الضجة على أشدها. بجانب تعليق هوانج، أطلقت شركة Arm معالج مركز البيانات الجديد باسم “معالج الذكاء الاصطناعي العام”. وقال سام ألتمان من OpenAI إنهم “بنوا بشكل أساسي ذكاءً اصطناعيًا عامًا”، وتقوم مايكروسوفت بالفعل بتسويق مختبر يركز على بناء ASI: تطور لما بعد تحقيق الذكاء الاصطناعي العام. يتم تمديد المصطلح ليشمل أي شيء يناسب المصلحة التجارية، ويبدو أنه يُستخدم بمعنى مرن.
موقف شوليه أبسط. إذا كان إنسان عادي بدون تعليمات يمكنه القيام بذلك، ونظامك لا يستطيع، فليس لديك ذكاء اصطناعي عام—بل لديك إكمال تلقائي مكلف جدًا ويحتاج إلى الكثير من المساعدة.
جائزة ARC لعام 2026 تقدم 2 مليون دولار عبر ثلاثة مسارات تنافسية، جميعها على منصة Kaggle. يجب أن يكون كل حل فائز مفتوح المصدر. الوقت ينفد، وحتى الآن، الآلات ليست قريبة من ذلك.
إخلاء المسؤولية: قد تكون المعلومات الواردة في هذه الصفحة من مصادر خارجية ولا تمثل آراء أو مواقف Gate. المحتوى المعروض في هذه الصفحة هو لأغراض مرجعية فقط ولا يشكّل أي نصيحة مالية أو استثمارية أو قانونية. لا تضمن Gate دقة أو اكتمال المعلومات، ولا تتحمّل أي مسؤولية عن أي خسائر ناتجة عن استخدام هذه المعلومات. تنطوي الاستثمارات في الأصول الافتراضية على مخاطر عالية وتخضع لتقلبات سعرية كبيرة. قد تخسر كامل رأس المال المستثمر. يرجى فهم المخاطر ذات الصلة فهمًا كاملًا واتخاذ قرارات مدروسة بناءً على وضعك المالي وقدرتك على تحمّل المخاطر. للتفاصيل، يرجى الرجوع إلى
إخلاء المسؤولية.
