ملخص سريع
- قالت شركة جوجل إن خوارزمية TurboQuant يمكنها تقليل عنق الزجاجة الرئيسي في ذاكرة الذكاء الاصطناعي بمقدار ستة أضعاف على الأقل دون فقدان الدقة أثناء الاستنتاج.
- انخفضت أسهم الذاكرة، بما في ذلك Micron و Western Digital و Seagate، بعد تداول الورقة البحثية.
- الطريقة تضغط على ذاكرة الاستنتاج، وليس أوزان النموذج، وتم اختبارها فقط في معايير البحث.
نشرت شركة جوجل للبحوث يوم الأربعاء خوارزمية TurboQuant، وهي خوارزمية ضغط تقلل عنق الزجاجة الرئيسي في ذاكرة الاستنتاج بمقدار 6 أضعاف على الأقل مع الحفاظ على دقة صفرية.
من المقرر تقديم الورقة في مؤتمر ICLR 2026، وكان رد الفعل على الإنترنت فوريًا.
وصفها المدير التنفيذي لشركة Cloudflare، ماثيو برنس، بأنها لحظة DeepSeek الخاصة بجوجل. وانخفضت أسعار أسهم الذاكرة، بما في ذلك Micron و Western Digital و Seagate، في نفس اليوم.
هل هو حقيقي؟
كفاءة التكميم (Quantization) إنجاز كبير بحد ذاته. لكن “فقدان الدقة الصفر” يحتاج إلى سياق.
تستهدف TurboQuant ذاكرة التخزين المؤقت KV — وهي جزء من ذاكرة GPU التي تخزن كل ما يحتاجه نموذج اللغة ليذكره أثناء المحادثة.
مع زيادة نوافذ السياق إلى ملايين الرموز، تتضخم تلك الذاكرات إلى مئات الجيغابايتات لكل جلسة. هذا هو عنق الزجاجة الحقيقي. ليس قوة الحوسبة، بل الذاكرة الخام.
تحاول طرق الضغط التقليدية تقليل تلك الذاكرات عن طريق تقريب الأرقام إلى الأسفل — من أعداد عشرية 32-بت إلى 16، ثم إلى 8، ثم إلى 4-بت أعداد صحيحة، على سبيل المثال. لفهم الأمر بشكل أفضل، فكر في تقليل دقة صورة من 4K إلى Full HD، ثم إلى 720p وهكذا. من السهل أن تميز أنها نفس الصورة بشكل عام، لكن هناك تفاصيل أكثر في دقة 4K.
المشكلة: يجب عليهم تخزين “ثوابت التكميم” بجانب البيانات المضغوطة لمنع النموذج من أن يصبح غبيًا. تضيف تلك الثوابت من 1 إلى 2 بت لكل قيمة، مما يقلل من المكاسب جزئيًا.
تدعي TurboQuant أنها تلغي تلك الحمولة تمامًا.
تقوم بذلك عبر خوارزميتين فرعيتين. PolarQuant تفصل بين المقدار والاتجاه في المتجهات، وQJL (Johnson-Lindenstrauss المكمم) يأخذ الخطأ المتبقي الصغير ويقلله إلى بت إشارة واحد، موجب أو سالب، بدون تخزين ثوابت.
النتيجة، تقول جوجل، هي مقدر غير متحيز رياضيًا لحسابات الانتباه التي تدفع نماذج المحولات.
في معايير الأداء باستخدام Gemma و Mistral، تطابق TurboQuant الأداء بدقة كاملة تحت ضغط 4 أضعاف، بما في ذلك دقة استرجاع مثالية في مهام البحث عن إبرة في كومة قش تصل إلى 104,000 رمز.
للفهم لماذا تهم تلك المعايير، فإن توسيع سياق النموذج القابل للاستخدام دون فقدان الجودة كان أحد أصعب المشاكل في نشر نماذج اللغة الكبيرة.
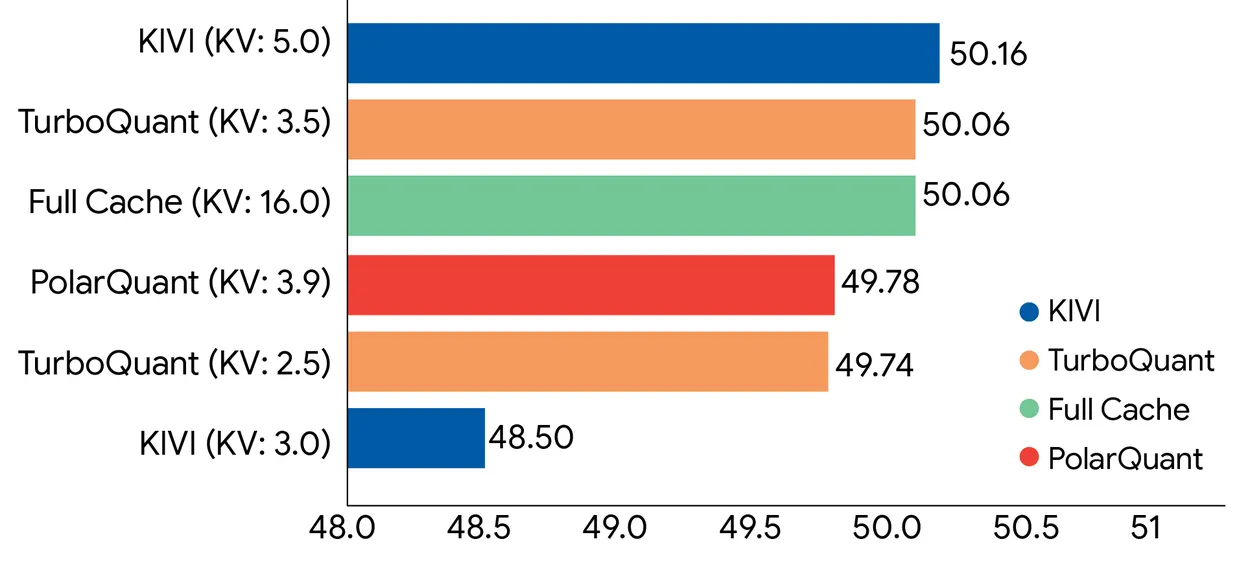
والآن، التفاصيل الدقيقة.
“فقدان الدقة الصفر” ينطبق على ضغط ذاكرة KV أثناء الاستنتاج — وليس على أوزان النموذج. ضغط الأوزان هو مشكلة مختلفة وأصعب. TurboQuant لا يتعامل معها.
ما يضغط عليه هو الذاكرة المؤقتة التي تخزن حسابات الانتباه أثناء الجلسة، وهي أكثر تسامحًا لأنها يمكن أن تُعاد بناؤها نظريًا.
هناك أيضًا الفجوة بين معيار نظيف ونظام إنتاجي يخدم مليارات الطلبات. تم اختبار TurboQuant على نماذج مفتوحة المصدر — مثل Gemma و Mistral و Llama — وليس على منصة جوجل الخاصة Gemini على نطاق واسع.
على عكس مكاسب الكفاءة في DeepSeek، التي تطلبت قرارات معمارية عميقة من البداية، لا يتطلب TurboQuant إعادة تدريب أو ضبط دقيق ويزعم أنه يضيف حمولة زمنية ضئيلة. نظريًا، يمكن دمجه مباشرة في خطوط استنتاج موجودة.
هذا هو الجزء الذي أربك قطاع أجهزة الذاكرة — لأنه إذا نجح في الإنتاج، فإن كل مختبر ذكاء اصطناعي رئيسي يعمل بشكل أكثر كفاءة على نفس وحدات GPU التي يمتلكها بالفعل.
تذهب الورقة إلى مؤتمر ICLR 2026. وحتى يتم تطبيقه في الإنتاج، ستظل عبارة “فقدان صفر” حبيسة المختبرات.
إخلاء المسؤولية: قد تكون المعلومات الواردة في هذه الصفحة من مصادر خارجية ولا تمثل آراء أو مواقف Gate. المحتوى المعروض في هذه الصفحة هو لأغراض مرجعية فقط ولا يشكّل أي نصيحة مالية أو استثمارية أو قانونية. لا تضمن Gate دقة أو اكتمال المعلومات، ولا تتحمّل أي مسؤولية عن أي خسائر ناتجة عن استخدام هذه المعلومات. تنطوي الاستثمارات في الأصول الافتراضية على مخاطر عالية وتخضع لتقلبات سعرية كبيرة. قد تخسر كامل رأس المال المستثمر. يرجى فهم المخاطر ذات الصلة فهمًا كاملًا واتخاذ قرارات مدروسة بناءً على وضعك المالي وقدرتك على تحمّل المخاطر. للتفاصيل، يرجى الرجوع إلى
إخلاء المسؤولية.
